
ティアフォー Perceptionチームの蓑田浩史です。近年のティアフォーの事業拡大に伴い、対応すべき課題が増え続ける中、既存の機械学習モデルを改善するリードタイムの長さが開発のボトルネックとなっていました。そこで、品質の良いデータのみを自動で抽出するシステムを開発し、全体のフローをシームレスにつなぐ体制を構築することで、リードタイムを大幅に改善しました。今回のブログでは、ティアフォーの3次元物体検知に関する機械学習モデルの課題と、それを解決するための取り組みを紹介します。
これまでのティアフォーでの機械学習に関するの取り組みと課題
「Autoware」は世界初の自動運転用オープンソースソフトウェア(OSS)であり、 主にLiDAR、カメラ、レーダー、慣性計測装置(Inertial Measurement Unit:IMU)、衛星測位システム(Global Navigation Satellite System:GNSS)などのセンサー情報が統合され、公道や閉鎖空間で認知・判断・操作の3つの動作を実行するスタックが実装されています。その中でも、Perceptionチームでは「Autoware」の認識モジュールを主に取り扱っています。LiDAR、カメラレーダーなどのマルチモーダルなセンサー情報を、機械学習とルールベースのハイブリッドで統合して推論結果を出力しています。認識モジュールの主なタスクとして3次元物体検知による自動運転車の周りの車や歩行者の位置推定タスクが挙げられますが、OSSの「Autoware」ではCenterPointという手法がコアのアルゴリズムとして採用されており、またその前後には様々な非機械学習ベースのモジュールが備わっています。詳細はこちらを参照ください。
近年はティアフォーの事業の拡大に伴い、対応する車種や環境が多様化し、求められる説明性のレベルも向上しています。例えば最近ではGLP ALFALINK相模原で自動運転レベル4の認可を取得し、石川県小松市で自動運転バスの通年運行を開始しました。また、都内一部地域でロボットタクシー事業を開始する計画もあり、対処すべき技術的課題も増えています。
 新宿を走るロボットタクシー
新宿を走るロボットタクシー
 GSM8 bus
GSM8 bus
当初のティアフォーの開発では、まとまったデータセットを定期的にアノテーションすることで、機械学習モデルの重みを改善するというフローを採用していました。しかしこの方式を採用していると、認識系の課題が発生した際、データセットに加えることによる機械学習モデル側での対処方法のリードタイム(T_ml)が、他モジュール側(主にROS application レイヤ)での対処方法のリードタイム(T_other)を大幅に上回ってしまい、結果として他モジュール側で対処を実施することが多くなるという問題がありました。そして、事業拡大による課題数増加に伴い、この問題は顕在化してきました。
T_ml >> T_other
これを機械学習的に表現すると、現場で発生した課題という「誤差」が、機械学習モデルの重みではなくルールベースモジュールの設計に対して「誤差逆伝播・学習」されてしまっていた、という状況です。これを解決するためには、
T_ml ≒ T_other
さらには
T_ml < T_other
という状況を作り出す必要があります。これにより、現場での課題を、ルールベースモジュールだけでなく、機械学習モデルの重みにも適切にフィードバックすることができるようになります。
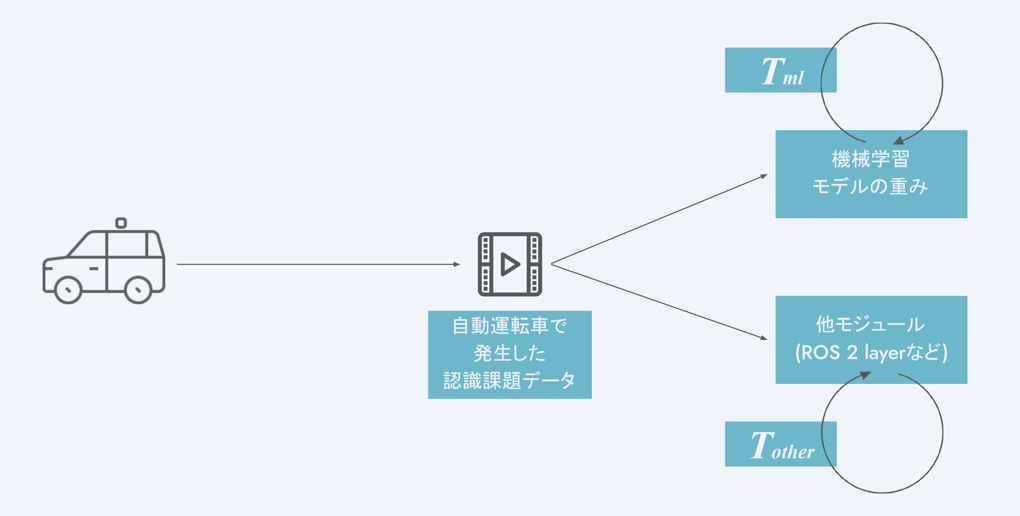
上記の課題を解決するために、フリートからデータを収集し、学習させるまでのフローをシームレスに実行する一連のシステムを完成させ、課題発生からモデル反映までのリードタイムを大幅に短縮しました。
継続的なデータ収集および学習のための基盤構築
自動運転で機械学習のシームレスな改善基盤を構築するには、下記のフロー構築が必要になります。
- 車両から収集したデータをクラウドなどのサーバーへデータをアップロードする
- データを適切に抽出・前処理し、アノテーション用フォーマットに変換する
- アノテーションを行い、結果をデータセットとして登録する
- 新規データセットを用いて学習を行う
- 学習済み重みをクラウドなどのサーバーから車両にデプロイする
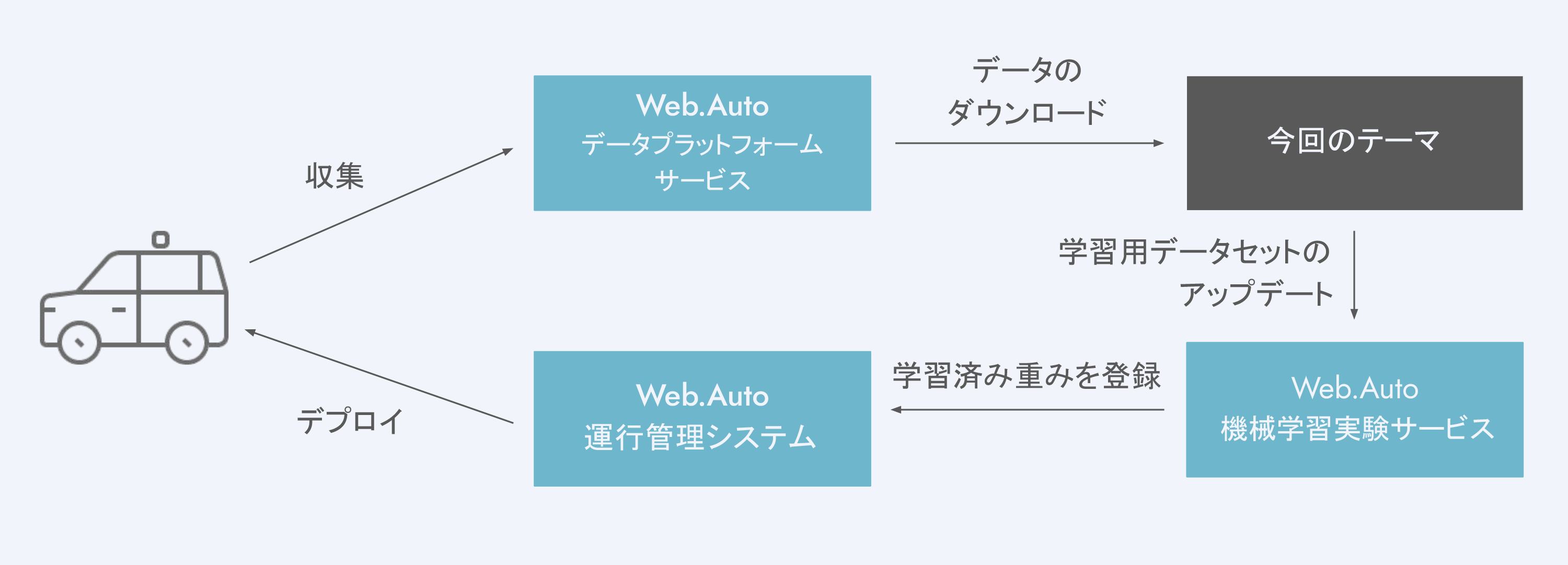
開発の初期段階から、上記の仕組みのベースはありましたが、継続的・自動的なフローにはなっておらず、下記の問題がありました。
- データの前処理の大部分を、手動で行う必要がある
- 低品質なデータが紛れ込む場合がある
- アクティブラーニングなどデータを適切に抽出する仕組みが存在せず、人手での選定が必要がある
データ前処理基盤の構築
ティアフォーの収集データはrosbag形式で、「Web.Auto」のデータプラットフォームサービスに日々登録されます。今回設計したフローは下記のとおりです。
- データプラットフォームサービスのAPIにアクセスし、毎日上がってくるrosbagを収集する
- 収集したrosbagを前処理し、学習用・評価用のデータとして定義しているt4datasetというフォーマットに変換する
- t4datasetのフォーマットに変換したrosbagをデータプラットフォームサービスに再登録する
これらをさらにミクロなサービスに分解し、コンテナサービスとして実装します。これらはローカルでも動作できる他、AWS Step Functionなどを活用し、クラウド上でも拡張性高く実行できる設計になっています。
なお、前処理では「Autoware」を実行する必要があります。これは、データ容量などの観点から、アノテーションに使うデータを直接保存することが難しく、点群データなどを生成し直す必要があるためです。更に、ティアフォーではロボットタクシーやロボバスなど様々な車種の自動運転車両に対応する「Pilot.Auto」を展開しており、本処理はそれに応じて立ち上げる「Autoware」の変更が必要になります。本設計では、「Web.Auto」が各車種について保持しているOTA(Over-The-Air)用のイメージを活用して実装を行っており、車両が実際に行う前処理と同一の処理を、ビルドすることなく再現可能です。
低品質なデータを弾く仕組みの構築
本基盤を用いて特に3次元物体検知の機械学習モデルを継続的に改善する上で、品質の良いデータのみを選定することが重要です。品質を低下させる要因は様々ですが、その中でも大きな影響を与える下記の2つの課題とその解決方法を紹介します。
- センサーデータにドロップが多い
- LiDARとカメラがうまくマッチしない
1つ目は、ネットワーク帯域によってはLiDARのパケットデータなどの一部がrosbagに保存できず、抜けや漏れが存在しているという問題です。定常版ではない実験用の「Autoware」や車両では発生することがあります。ドロップ率を元にデータを弾くことで解消はしますが、「特定の◯◯が写ったこのシーンをアノテーションしたい」という要望に十分応えられなくなる可能性があります。こちらはECU設計におけるネットワークトラフィック周りを随時見直すことで長期的な改善を進めています。ROS 2 ironよりデフォルトになるMCAPというフォーマットを採用することで改善することが確認されており、解消が進んでいます。
2つ目は、LiDARとカメラのキャリブレーション結果に誤りがある可能性がまず考えられますが、時刻同期という可能性も考えられます。こちらも定常版の車両であれば起きることはありませんが、開発初期段階で安定していない車両やシステムでは発生する可能性があります。また、運用面のミスにより発生する可能性もゼロではありません。本課題については、カメラ画像上に点群を重畳した動画を目視で適宜チェックし、運用面で対処していますが、LiDARとカメラの重畳を動的物体と静止物体の双方について合わせることは原理的に難しく、チェックする際も慣れが必要です。(LiDAR歪みの補正に関してはこちらのブログをご参照ください。)ティアフォーでもセンサーの時刻同期は大きなトピックとして取り組まれており、それらを統合して扱えるユニバーサルなセンサードライバ 「nebula」 の開発を行っています。こうした取り組みにより、目視による確認も徐々に不要となるロードマップをひいています。
情報量の多いデータを選出する仕組みの構築 ー アクティブラーニング
毎日車両から送られてくる膨大な量のデータのうち、その殆どはアノテーションしてもモデル性能の向上への寄与率が限られており、適切にデータを選定する必要があります。そのため、今回作成した学習基盤は、多数の選定アルゴリズムを容易に挟み込める設計にしてあります。
今回は最初のステップとして、教師モデル(teacher model)と車載モデルの推論結果の比較により推論結果の不確かさを近似的に計算し、それを基にアノテーションするべきフレームを定めるというアルゴリズムを開発しています。これは機械学習における「アクティブラーニング」と呼ばれる手法と似た発想であり、能動的に学習する対象を選定していくというアプローチです。ここは近い将来視覚言語モデル(Vision Language Mode:VLM) などの基盤モデルの活用も期待される部分です。
3次元物体検知の教師モデルについては、現在はBEVFusionをベースに構築しています。もちろん教師モデル自体にも誤検知はあるものの、CenterPointなどの車載モデルと誤差の傾向(間違えやすいクラスなど)は異なるため、効率よくアノテーションすべきデータを抽出することが出来ます。
まとめ
今回は、ティアフォーにおける3次元物体検知に関する機械学習モデルの継続的なアップデートに関する取り組みを紹介しました。大量の実データを適切に取り扱うためのパイプラインを構築することで、「Autoware」の機械学習側からの改善をこれからも推進していきます。また、今回のパイプライン構築では「機械学習が既に導入されている」「まだデータ面からの改善の余地がある」という観点から3次元物体検知を取り扱いましたが、「Autoware」ではこれ以外にも様々なタスクを機械学習で置き換える開発が並行して進行しており、順次パイプラインに載せていく予定です。
Koji Minoda | 蓑田 浩史
Perceptionチーム
東京大学大学院・航空宇宙工学科修士課程修了。2022年4月入社。2020年11月からパートタイムエンジニアとして勤務。現在はPerceptionチームで、データセット構築による機械学習モデルの性能改善業務をリード。
ティアフォーでは、「自動運転の民主化」というビジョンに共感を持ち、自らそれを実現する意欲に満ち溢れた新しい仲間を募集しています。
多くの職種で採用をしています。詳細は、ティアフォーの「求人ページ」をご覧ください。カジュアル面談をご希望の方は、応募する際に「カジュアル面談希望」と記載してください。
「どの職種で自分の経験を活かせるかが分からない」「希望する職種が見つからない」などの場合は、ぜひ「キャリア登録」をお願いします。
お問い合わせ先
- メディア取材やイベント登壇のご依頼:pr@tier4.jp
- ビジネスや協業のご相談:sales@tier4.jp
ソーシャルメディア
X (Japan/Global) | LinkedIn | Facebook | Instagram | YouTube
関連リンク