こんにちは。ティアフォーで自動運転ソフトウェア開発を行っている村上です。今回はDeep Learningを使った三次元物体認識の手法を紹介していきます。

自動運転におけるDeep Learning
自動運転では主に周りの環境を認識する際にDeep Learningを用いることが多いです。画像認識アルゴリズムであるSSD *1 やYOLO *2 が有名なものになります。
Deep Learningは認識以外の分野にも応用されています。例えば、自動運転における判断 *3 や車両制御 *4 に応用するような論文も出てきていたりします。
点群を処理するためのDeep Learning
そんな中で今回はDeep Learningを点群処理に応用したアルゴリズムを紹介したいと思います。
そもそも、なぜ点群を処理するためにDeep Learningが必要なのでしょうか?理由は高精度の物体認識と形状推定を実現するため、です。
ざっと従来手法
2011年にStanfordから発表された、DARPA Urban Challengeの研究成果を取りまとめた論文 *5 *6 では以下のような点群による認識のパイプラインが提案されました。
下のグラフのように、点群に対して順番に様々な処理をしていくようなパイプラインになっています。

従来のパイプライン
しかし、このパイプラインでは自動運転で求められるような高精度の認識が難しいという問題がありました。
従来手法での問題
いくつか問題がありましたが、一つ挙げるとすれば、「クラスタリング」において、二つの物体が隣り合っている場合、区別することが難しいという問題がありました。

Euclidean Cluster結果
右側の画像でクラスタリング手法の一つである、Euclidean Clusterの結果を表示しています。前方左にバイク、前方右に自動車があるような状況ですが、二つの物体を一つの物体として認識しており(同じピンクの色で認識)、それぞれの物体を区別することができていませんでした。
形状推定の必要性
また、自動運転におけるPerceptionの難しさの一つに隠れ(オクルージョン)の問題があります。従来のパイプラインでは一部の物体形状しか得られない状態において、物体全体の形状を推定することが困難でした。
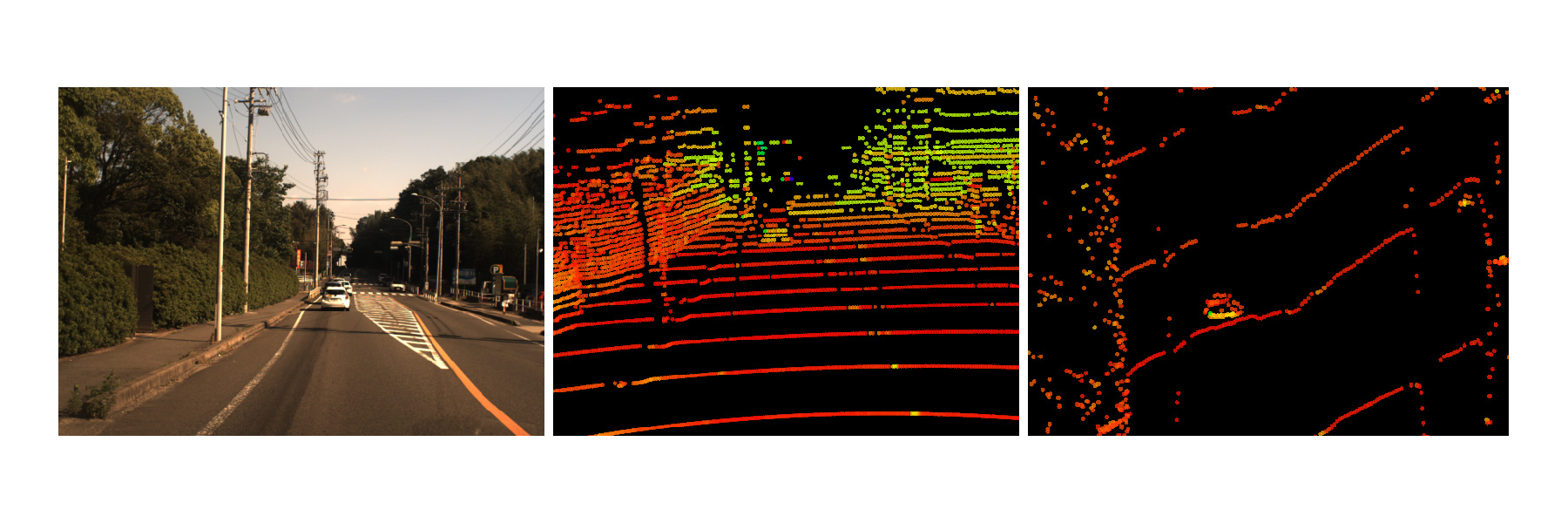
左から画像、同一視点からの点群、鳥瞰方向からの点群
上の画像は前方の車両を様々な角度から見たものです。一番右の鳥瞰方向の画像では、前方の車の形状が分かりにくいことを示しています。
実際の物体は下の画像のように存在します。このように物体全体の形状を推定することは、TrackingやPlanningなどの自動運転における重要なプロセスの中で非常に役に立ちます。
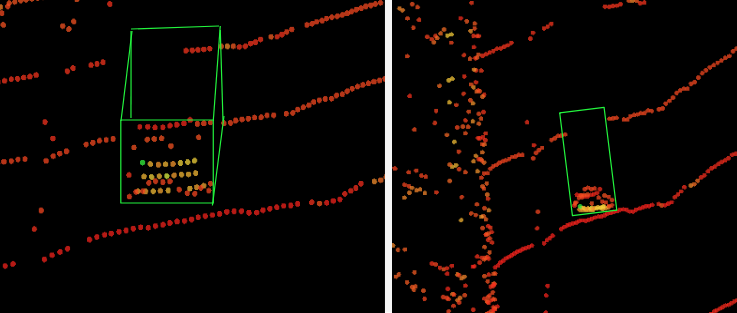
実際の形状を緑枠で表示
Deep Learningで可能なこと
従来の手法では点群を順番に処理していましたが、DeepLearningベースの手法ではEnd to Endで最適化されたクラス分類と形状推定をすることができます。
これは従来のパイプラインにおける「地面除去」、「クラスタリング」、「クラス分類」といった処理を暗に内包していると言えます。
また、物体の形状についても事前知識を利用することによって、従来手法では成し得なかった全体形状の高精度な推定が可能となりました。
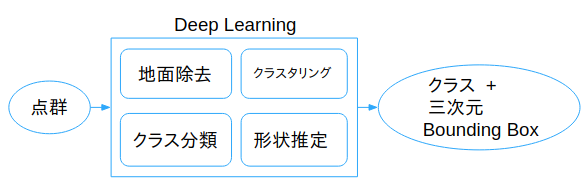
Deep Learningのパイプライン
三次元物体認識アルゴリズム「PointPillars」の紹介
従来手法では達成できなかった「高精度の物体認識と形状推定」をするために、今回「PointPillars」*7 を実装しました。
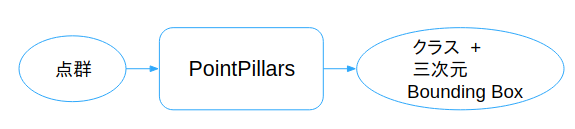
今回のパイプライン
ざっと類似手法
2016年に発表されたMV3D *8 では画像と点群を使用し、Faster R-CNN *9 を模した構造で特徴量抽出した後にFusionをして三次元Bounding Boxを生成しました。
2017年にAppleの研究員が発表したVoxelNet *10 では、PointNet *11 をベースにしたPoint単位の特徴量抽出とVoxel単位での局所的な特徴量計算を合わせて行うことで、MV3Dを上回る性能を達成しました。
2018年に発表されたSECOND *12 はVoxelNetの構造を参考にしながら、一部にSparse Convolutionを適用することでモデルの軽量化と性能向上を達成しました。
なぜ「PointPillars」
SECONDとほぼ同時期に発表されたのがPointPillarsでした。VoxelNetを踏襲しながら、Voxel単位の特徴量抽出ではなくPillar(柱)単位での特徴量抽出と2D-convolution使用による軽量化された構造が特徴です。
今回、なぜ数あるアルゴリズムの中からPointPillarsを選択したかというと、処理速度と予測精度のバランスが優れているからです。
予測精度は他のアルゴリズムと比べてトップクラスであると同時に、処理速度は類似手法と比較し最も早く動作するアルゴリズムであり、16ms(約62Hz)で動作することが論文内で述べられています。
下の画像 *13 ではクラス別の比較項目の中で、PP(PointPillars)が他のアルゴリズムに比べて、予測精度と処理速度の二つの点から優れていることが分かります。
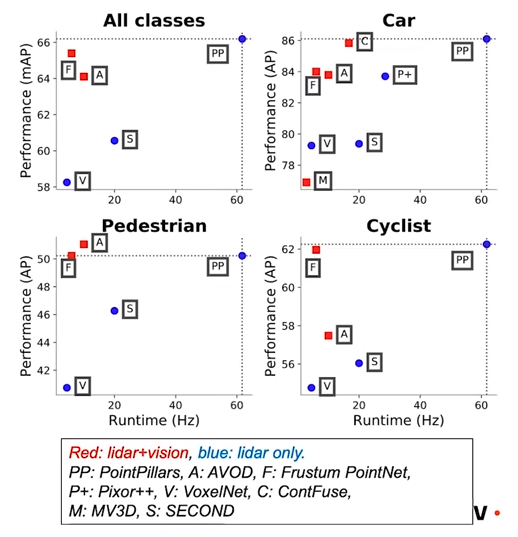
PointPillarsと類似手法比較
ネットワーク構造はVoxelNetとくらべてPillar単位の特徴量抽出や2D-convolutionの使用により、軽量化されています。
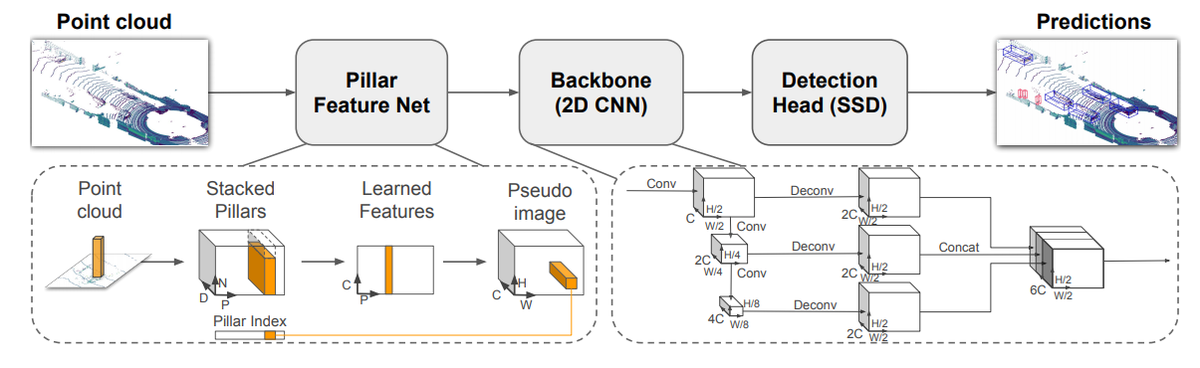
PointPillarsネットワーク構造の概略図
CUDAとTensorRTによる高速化
従来手法と比べた大幅な高速化は二つの要因から達成されました。 一つはネットワーク構造のスリム化。そして、もう一つはTensorRTと呼ばれるDeep Learningの推論を高速化するLibraryの使用です。
TensorRTは便利ですが、対応しているレイヤーの種類が限られている、という欠点があります。
実際に、PointPillarsで使用したいと考えていた"Scatter"と呼ばれるレイヤーが存在しなく、自身で実装する必要がありました。
最初はCPU側でコードを書いていたのですが、メモリ転送の時間コストが高かったため、この部分をCUDAで実装しました。
また、点群の前処理と後処理においてもCUDAによる実装をすることで、計算効率化とメモリ転送コストの削減を達成しました。
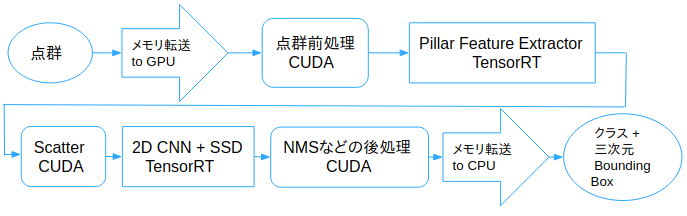
コード実装の概略図
Deep Learningによる点群処理手法の問題点のうちの一つが、その処理速度が遅いことでした。たとえば類似手法で紹介したVoxelNetでは225msかかっており、LIDARのセンサー周期が100msで動いていることを考慮すると、自動運転で扱うことが難しいアルゴリズムでした。
元論文では優れたネットワーク構造とTensorRTによって16msで動作することを発表しました。
さらに今回の実装では、前処理・後処理をCUDA化することによって全体処理時間を12msまで短縮しました *14 *15。
下の動画では、Autowareに組み込まれているPointPillarsをKITTI Raw Dataset で評価した結果になります。
KITTI dataset*16 is published under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0.
最後に
最後になりますが、現在ティアフォーでパートタイマーとして勤務している、東京大学、創造情報学専攻の村松さんにはPointPillarsのネットワーク実装においてアドバイスをいただきました。 ありがとうございました。
*1 W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg. SSD Single shot multibox detector. In ECCV, 2016.
*2 J. Redmon and A. Farhadi. YOLO9000: Better, Faster, Stronger. In CVPR, 2017, pp. 6517–6525.
*3 S. Shalev-Shwartz, S. Shammah, and A. Shashua. Safe, multiagent, reinforcement learning for autonomous driving. In NIPS Workshop on Learning, Inference and Control of Multi-Agent Systems, 2016.
*4 G. Williams, N. Wagener, B. Goldfain, P. Drews, J. M. Rehg, B. Boots, and E. A. Theodorou. Information theoretic MPC for model-based reinforcement learning. In ICRA, 2017.
*5 A. Teichman, J. Levinson, and S. Thrun. Towards 3D object recognition via classification of arbitrary object tracks. In ICRA, 2011, pp. 4034–4041.
*6 J. Levinson, J. Askeland, J. Becker, J. Dolson, D. Held, S. Kammel, J. Kolter, D. Langer, O. Pink, V. Pratt, M. Sokolsky, G. Stanek, D. Stavens, A. Teichman, M. Werling, and S. Thrun. Towards fully autonomous driving: Systems and algorithms. In Proc. IEEE IV, Jun. 2011, pp. 163–168.
*7 A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom. PointPillars: Fast encoders for object detection from point clouds. arXiv:1812.05784, 2018.
*8 X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-view 3d object detection network for autonomous driving. In CVPR, 2017.
*9 S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015.
*10 Y. Zhou and O. Tuzel. Voxelnet: End-to-end learning for point cloud based 3d object detection. In CVPR, 2018.
*11 C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In CVPR, 2017.
*12 Y. Yan, Y. Mao, and B. Li. SECOND: Sparsely embedded convolutional detection. Sensors, 18(10), 2018.
*13 https://youtu.be/p5AtrKqQ3Fw?t=2203
*14 https://github.com/autowarefoundation/autoware/tree/master/ros/src/computing/perception/detection/lidar_detector/packages/lidar_point_pillars
*15 CPU:Core i7 8700K, GPU:GTX-1080ti, Tested with a rosbag in the office
*16 http://www.cvlibs.net/datasets/kitti/
オープンソースのソフトウェアを一緒に開発していきませんか?
ティアフォーでは、「自動運転の民主化」というビジョンに共感を持ち、自らそれを実現する意欲に満ち溢れた新しい仲間を募集しています。
Media Contact
pr@tier4.jp
Share the post
LinkedIn | Twitter | Facebook | Instagram