
プロジェクト背景と自動運転における3次元物体認識性能向上
ティアフォーと松尾研究所は、2020年から共同研究を開始し、2024年で5年目を迎えました。本共同研究では自動運転レベル5の実現を目指し、短期テーマと長期テーマという2つの時間軸で課題解決に取り組んでいます。
短期テーマでは、ティアフォーが開発を主導する自動運転用のオープンソースソフトウェア「Autoware」の機能改善に取り組んでいます。具体的には、松尾研究所が持つ深層学習に関する知見を活かし、自動運転の現場に近い立場から、「Autoware」が有するモジュールの認識精度や予測精度の改善などを進めています。
一方、長期テーマでは、松尾研究所が注力している世界モデルの自動運転領域への応用に取り組んでいます。世界モデルは、観測情報から実世界の変化を学習するモデルです。この技術を自動運転領域に応用することで、より高次な自動運転技術の実現に貢献できると考え、基礎研究的な立場から研究開発を進めています。
それぞれ研究開発の状況や、目標としている時間軸は異なりますが、将来的には各テーマが有機的に働き、本共同研究の最終目標の達成につながると信じています。
本記事を含め3回にわたり、2023年度の取り組み内容を紹介します。最初の2本は短期テーマで取り組んだ課題とその問題解決のためのアプローチを、最後の1本は長期テーマに焦点を当てた方針と取り組みの一部を紹介します。短期テーマの取り組みを石橋 英一郎さん・上田 紘途さん・佐伯 匡斗さん・髙田 直輝さん・山下 佳威さんのメンバーで報告し、本記事ではその概要の一部をお伝えします。
共同研究内容1:CenterPointの時系列安定化
背景
「Autoware」では、LiDAR点群での物体検出のためにCenterPoint [1]というモデルを使用しています。検出能力の向上のために、時刻の近い数フレームを結合し、点群密度を増大させる手法を利用しています(以降、この手法をDensificationと呼びます)。これにより、推論したい単一フレームにおける検出能力は向上します。しかしながら、時間横断的なフレームにおける検出能力、つまり検出安定性であったりオクルージョンに対する検出能力の向上には期待できません。自動運転における認識機能の精度向上を考える上ではこちらの能力も重要となってきます。そのための手法として、結合する点群のフレーム数を多くすることが挙げられますが、大幅な計算量の増加と移動物体に対する不正確な結合によって、実車両で利用することやそもそもの精度向上が難しくなります。そこで今回は、検出を安定させるための時系列安定化の手法を3つ紹介し、自分たちで実装し直して実験した結果や考察についても述べていきます。
概要
少量の計算コストで、長い時系列を扱うことができる手法を3つ紹介します。
INT: Towards Infinite-frames 3D Detection with An Efficient Framework [2]
この論文は、点群、BEV特徴マップ(3D BackBoneの出力)、予測マップ(2D BackBoneの出力)の3種類のデータを保存するMemory Bankを持ち、それらを融合しています。ざっくり説明すると、点群はBBox内のみの結合、BEV特徴マップはConvolutionでChannelを半分にしてからその方向で結合、予測マップは平均をとった後に結合します。これにより、計算の負荷を増大させずに融合できます。また、これまで長い時系列を学習させることは難しく、メモリ増大や勾配爆発や消失、異なるモデルからの出力による矛盾などの問題がありました。この問題の解決のために、学習が進むにつれて徐々に長い時系列を入力していくような手法(DTSL)を使っています。
SUIT: Learning Significance-guided Information for 3D Temporal Detection [3]
この論文は、BEV特徴マップのみでの融合手法を提案しています。加えて、BEV特徴マップ全体を使うことなく検出物体の付近のみを利用することで、効率的に処理しています。また、周囲の物体が移動することによる各時刻での座標の差分を、内部モデル(3層のConvolution)で予測、対応することにより、性能の向上を果たしています。
MoDAR: Using Motion Forecasting for 3D Object Detection in Point Cloud Sequences [4]
この論文は、点群のみでの融合手法を提案しています。検出された物体を1つの点として扱い、一般的な点群とChannel長を揃えて結合します。この物体の点に対し、TrackingとPredictionを利用することによってより正確かつ、長期的な座標の差分を打ち消すことができます。これら2つのモジュールは自動運転に組み込まれているため、計算コスト自体の増加は抑制できます。
実装
前述した3種類の手法を、「Autoware」で利用する構成のCenterPointにそれぞれ適用させました。基本的にはモデルのアーキテクチャ、データをシーケンシャルに取り出せるようにするサンプラー、Augmentationや各時刻における自己位置の差分に対する座標変換処理を実装することで実現できます。今回の実験においては、Predictionモデルを準備するのに時間がかかるため、検出器の結果をそのまま利用します。加えて、オンラインで動作させられるように実装を加えたモデルも実験します。
結果
Densificationを利用したCenterPoint(3 Frames)に対して、INTとMoDARでは精度劣化、SUITでは若干の精度向上が確認されました。この結果から、移動物体に対して座標のずれを埋めることができる手法が効果的であると考えます。また、3つの手法全てでlatencyを削減でき、処理する点群数を抑えることによる効果を確認できました。しかしながら、mAPでは時系列の安定性を図ることは難しいため、Densificationを利用したCenterPoint と、代表としてSUITの推論結果を定性的に比較しました。結果だけ述べると、SUITはオクルージョンになっている物体でも検出できていることが確認できました。また、物体の時系列的な検出安定性も高まっていることが確認できました。その反面、False Positiveが出現している例もあります。この原因については、検出結果をフィードバックするアーキテクチャを採用しているため誤検出した結果もフィードバックされてしまっているためだと考えます。つまり、単一フレームのモデル自体の性能がある程度優れていないと、効果が得られにくいのだと考えます。
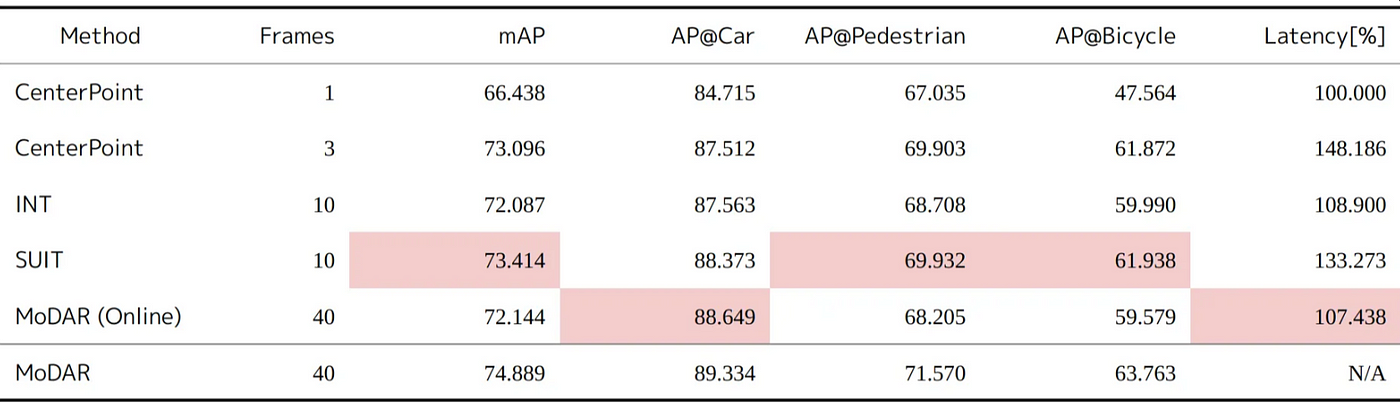
CenterPointにINT、SUIT、MoDARを適用した結果
まとめ
今回、CenterPointの時系列安定化と称して3つの手法を実装し、考察しました。結果から、時系列安定化やmAPに起因するのは、検出した物体を各時刻に合った座標を予測して融合することだと考えます。また、False Positiveについては、検出した物体のランダムドロップなどの時系列特有のAugmentationなどで対策できる可能性があると考えています。今後も実験を進め、「Autoware」の認識機能の改善を進めていきます。
参考文献
[1] Tianwei Yin, Xingyi Zhou, and Philipp Krähenbühl. “Center-based 3D Object Detection and Tracking.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[2] Jianyun Xu, Zhenwei Miao, Da Zhang, Hongyu Pan, Kaixuan Liu, Peihan Hao, Jun Zhu, Zhengyang Sun, Hongmin Li, Xin Zhan. “Int: Towards infinite-frames 3d detection with an efficient framework.” In Proceeding of the IEEE/CVF European Conference on Computer Vision (ECCV), 2022.
[3] Zheyuan Zhou, Jiachen Lu, Yihan Zeng, Hang Xu, Li Zhang. “SUIT: Learning Significance-guided Information for 3D Temporal Detection.” In Proceeding of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023.
[4] Yingwei Li, Charles R. Qi, Yin Zhou, Chenxi Liu, Dragomir Anguelov. “MoDAR: Using Motion Forecasting for 3D Object Detection in Point Cloud Sequences.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
共同研究内容2:CenterPointの車両速度推定精度の評価
背景
「Autoware」では、Detectionの結果を安定化させるためや、物体に固有のIDを付与するため、後段でTrackingを行っています。これらの機能はカルマンフィルタ [1] により実現されています。また、その内部では時刻の異なる検出物体のマッチングのため、速度を新しく推定しています。この推定自体は、カルマンフィルタの更新によって安定していくのですが、初期速度が不明であるため、新しい検出物体のマッチングが不安定になります。具体的には、新しい検出物体が静止しているのか動作しているのかを区別することができず、異常な挙動を示すこともあります。この問題を解決し、物体の検出初期から安定化させるためには、初期速度を適切に設定する必要があります。そこでCenterPointの速度推定を利用することを検討しました。事前調査として、速度推定がどの程度の精度を保持しているのかを評価しました。
概要
まず、速度を評価するための指標を2つ用意しました。1つ目は速度の大きさの差分で、2つ目は速度のコサイン類似度です。また、定性的な評価のために可視化もしました。
結果
ティアフォー社内のデータセットで学習し、検出された全てのBounding Boxに対し、対応するGround Truth Bounding Boxとの間で評価しました。その結果を表1に示します。速度の大きさの差分については、94.9%が誤差10 km/h以内に収まっています。これはフレーム間で最大0.278 m以内の誤差となります(LiDARの周期を10 Hzとする)。速度のコサイン類似度については、49.4%が類似度0.98以上に収まっています。これはフレーム間で最大11.5°以内の誤差となります。残りはそれ以上の誤差になっていますが、そのうち96.6%が0〜5 km/hの低速物体となっています。

速度の大きさと角度の評価
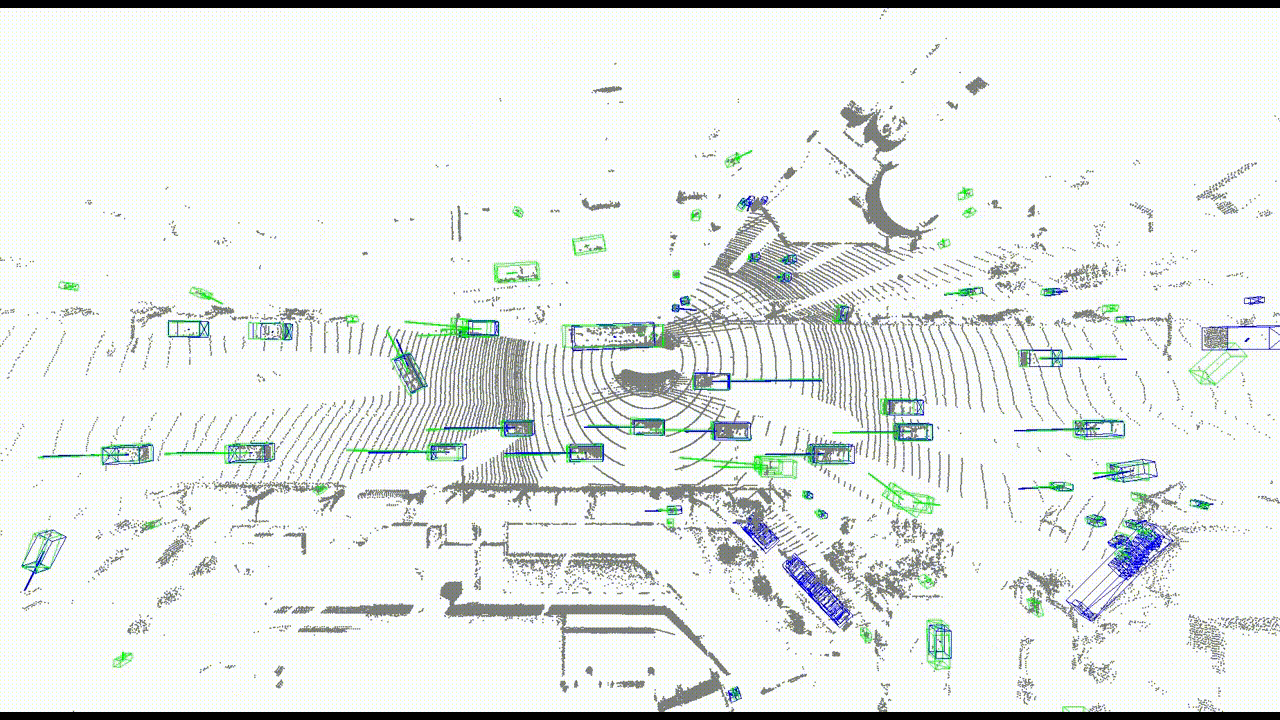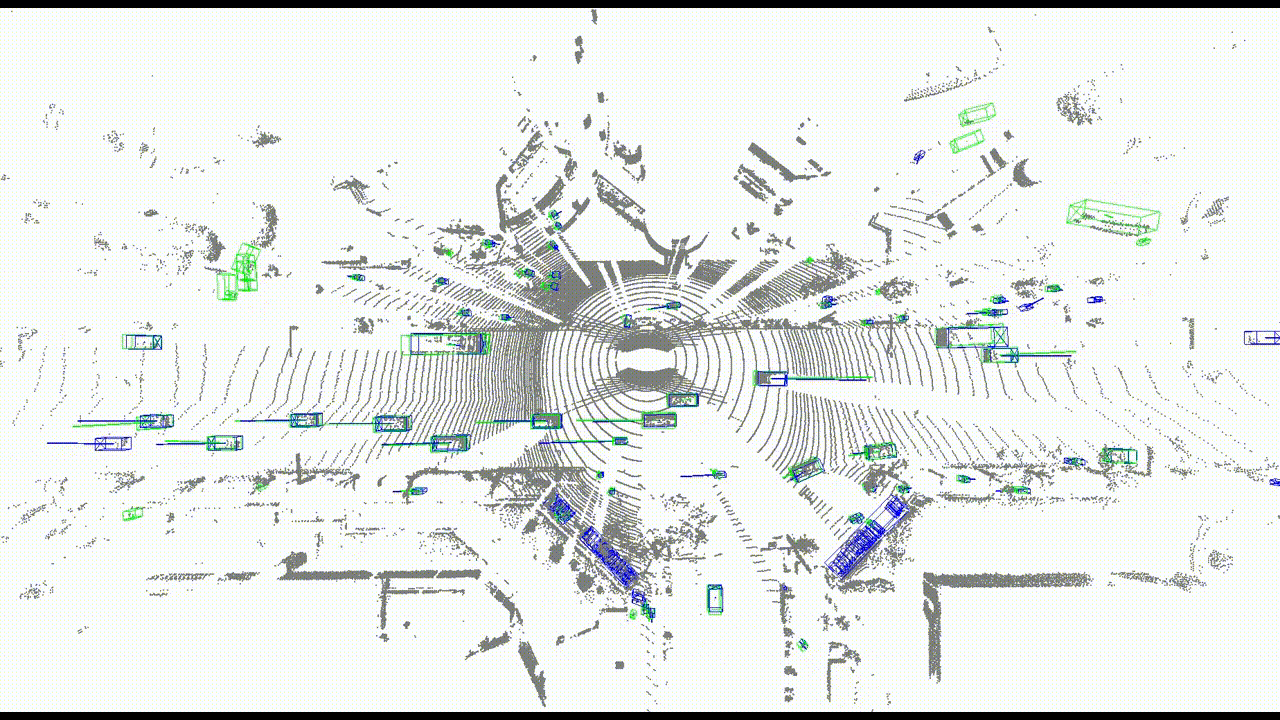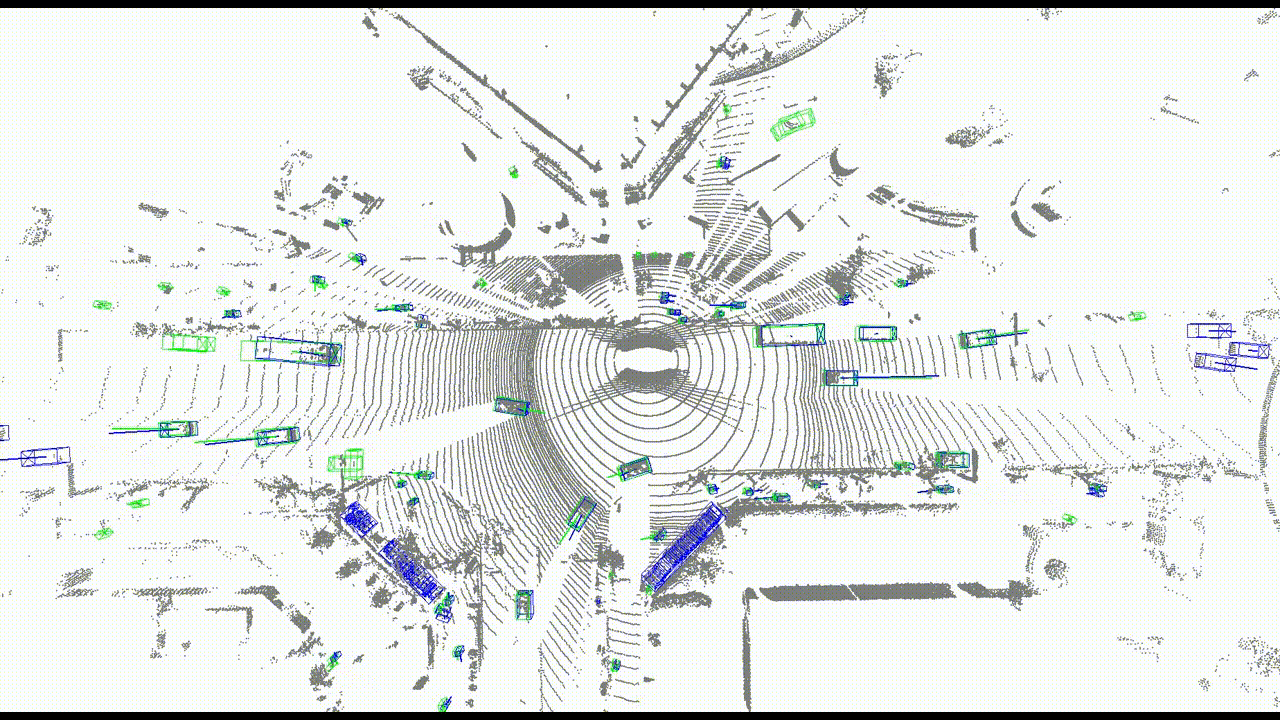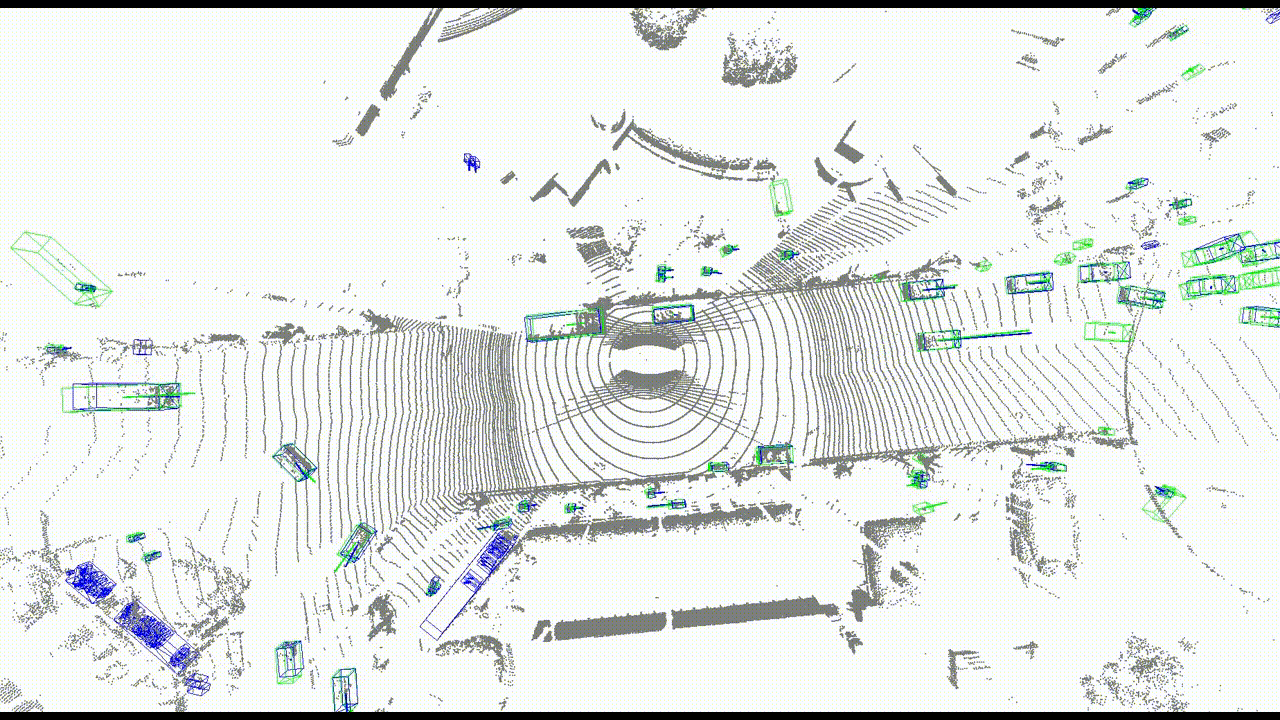
速度ベクトルの可視化
まとめ
今回、Trackingにおける安定化のため、CenterPointの速度推定がどの程度の精度なのかを調査しました。その結果、速度推定は利用可能レベルであると考えます。低速物体に関しては向きを正しく推定できませんが、速度自体が小さいため、影響は少ないと言えます。今後は、この特性を理解しつつTrackingに取り込むための手法や、速度の共分散を追加で推定することによるさらなる安定化に取り組もうと考えています。
参考文献
[1] R. E. Kalman. “A new approach to linear filtering and prediction problems.” J. Fluids Eng., 82(1):35–45, 1960.
共同研究内容3:CenterPointでのMap情報の利用
背景
自動運転車両の周囲環境認識において、LiDARで取得した点群や、カメラで取得した画像を用いた、3次元物体検出手法が大きな役割を果たしています。しかし、入力として使われるLiDAR点群やカメラ画像などのデータには、車両の向きを推定する情報が乏しいため、車両の方向を逆向きに推定してしまう場合があります。 これを改善するため、車線の情報が入った地図データを入力に加えることで精度向上につなげようというアプローチをとりました。
概要
車線情報を物体検出手法に入力する手法にはLaneFusion [1] があり、この手法では車線の方向を色相で表現し、走行可能領域をグレーで塗りつぶしたRaster地図を入力に用いる手法が提案されています。この手法により得られた効果として、LiDARオンリーの3次元物体検出手法であるCenterPoint [2] をベースモデルとして、Argoverse v1データセットにてmAP+6.56、AOS+10.65の精度向上を達成しています。LaneFusionのアーキテクチャは論文内では様々なものが試されていますが、最も検出性能が向上したものは以下の図のように車線に着色した画像から特徴量を得るバックボーンを点群のものとは別に用意するParallel Backbone方式のものでした。
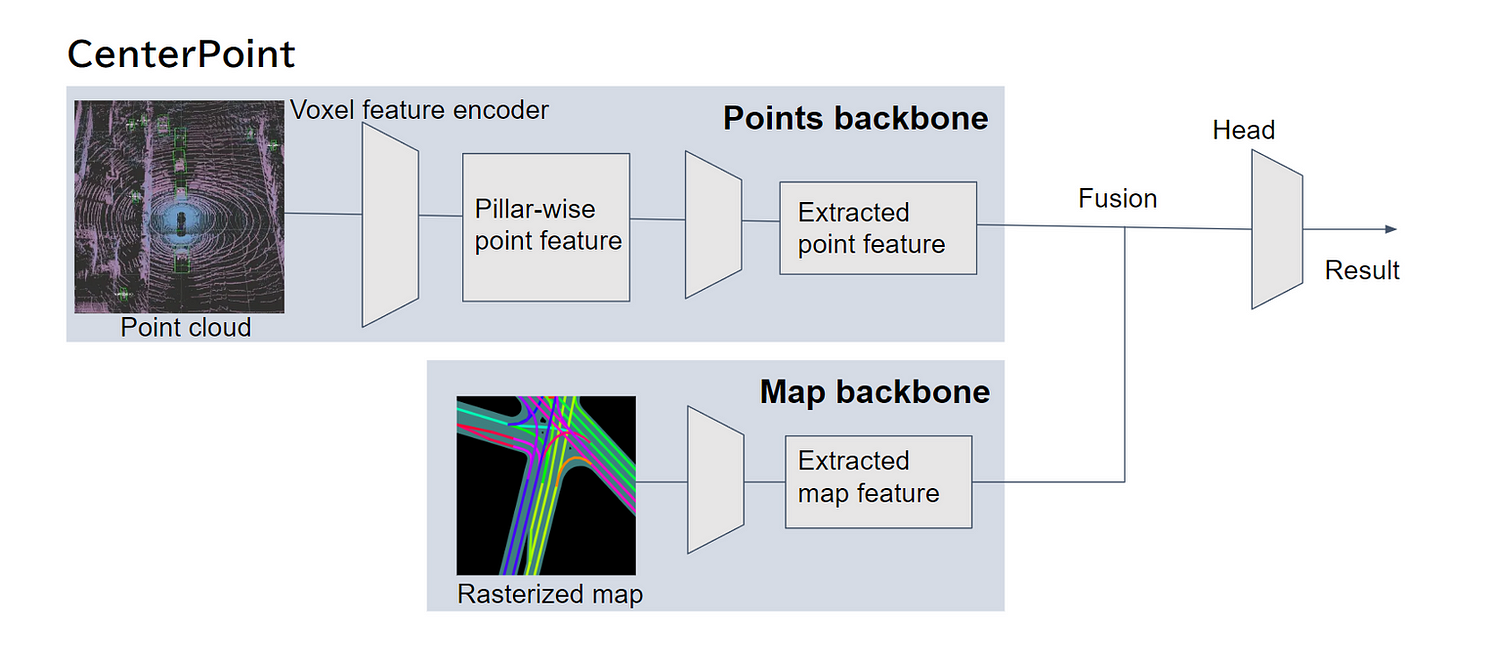
LaneFusionのアーキテクチャ (Parallel Backbone)
今回はこちらのアーキテクチャを採用し、ティアフォーが取得した国内データセットで性能を調査しました。
実装
ティアフォー社内の学習フレームワークにて実装されているCenterPointに対し、追加実装しました。ティアフォーデータセットを利用するにあたり、「Autoware」で使用されているLaneletという地図形式に対応する必要がありました。ここで、LaneletライブラリはC++で記述されており、Python APIも用意されているのですが、機能面で完全ではありませんでした。そのためC++とCythonを使用し、Laneletライブラリで地図を読み込んで車線画像を生成するPythonモジュールを実装しました。
実験
ティアフォーデータセットで30 Epochの学習を行いました。結果としては、通常のCenterPointとの間に大きな改善は見られませんでした。学習時の損失の推移(下図参照)を見ると、地図情報を入れたものの方が通常のCenterPointよりも速く学習が進んだ一方、同等の精度に落ち着いたことがわかります。このことから、車線情報については、学習を進めるにつれて入力された他の情報から同等の情報の推測が可能となった可能性が考えられます。
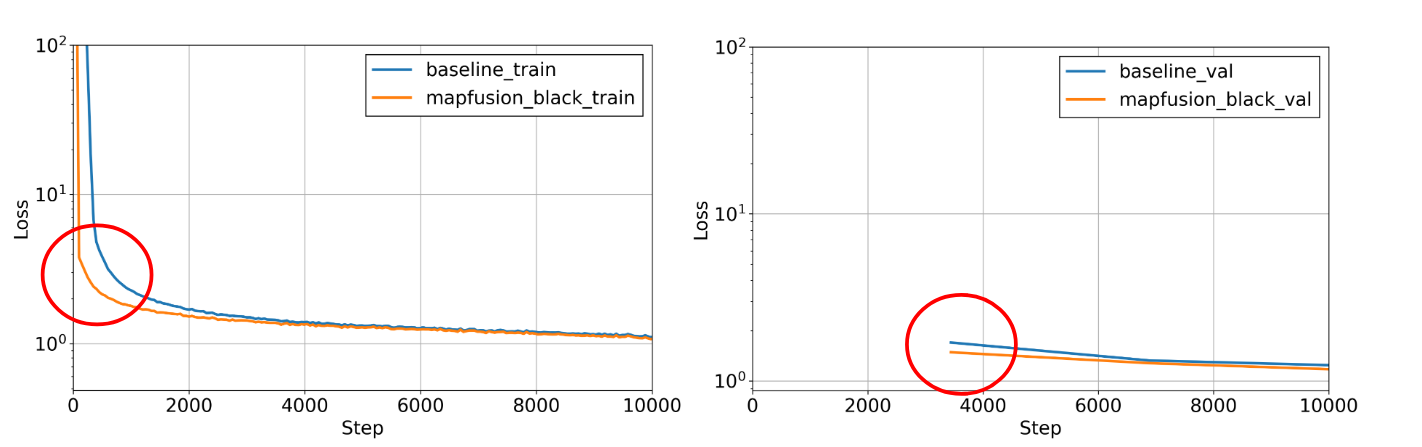
ティアフォーデータセットでの学習時の損失推移
まとめ
今回の実験では、物体検出手法に対して車線方向の情報を導入することによる精度向上効果について、国内データセットや過去の研究より大規模な海外データセットを用いて確認しました。その結果、車線情報の導入によって学習が速く進みますが、最終的な精度については変化が小さくなりました。松尾研究所では今後も様々な手法に取り組み、「Autoware」の各種モジュールの精度改善を進めてまいります。
参考文献
[1] Taisei Fujimoto; Satoshi Tanaka; Shinpei Kato., “LaneFusion: 3D Object Detection with Rasterized Lane Map”, 2022 IEEE Intelligent Vehicles Symposium (IV). [2] Tianwei Yin, Xingyi Zhou, , Philipp Krähenbühl., “Center-based 3D Object Detection and Tracking”, CVPR 2021.
共同研究内容4:Dynamic Sparse Voxel Transformer(DSVT)
背景
近年、3次元物体検出の分野では、Transformerベースの手法が大きな注目を集めています。
これまで、3D物体検出はポイントクラウドや3Dボクセルを直接処理するCNNベースの手法が主流でした。しかし、CNNは局所的な特徴を捉えることに長けていますが、疎な点群データでは重要な特徴が広範囲に分散している可能性があり、特徴を捉えにくいという問題がありました。
これに対してTransformerはAttention機構を用いることで、疎な点群データの中から重要な特徴を選択的に捉えることができます。
今回はTransformerベース手法の中でもDSVT(CVPR 2023)について取り上げます。
概要
この手法は既存のCenterpointからバックボーン部分をtransformerベースにしたものになります。
全体の流れとしてはポイントクラウドを入力とし、Voxelizationが行われます。そこでx, y方向で区切りボクセル化した後、バックボーン(下図の点線で囲まれた部分)で3次元特徴量を抽出し、BEV Backboneへ通され、そこで2次元特徴が抽出されPerception Headで最終的な物体検出が行われます。バックボーン部分ではDSVT Blockというものが並べられていて、この手法の肝となる部分です。
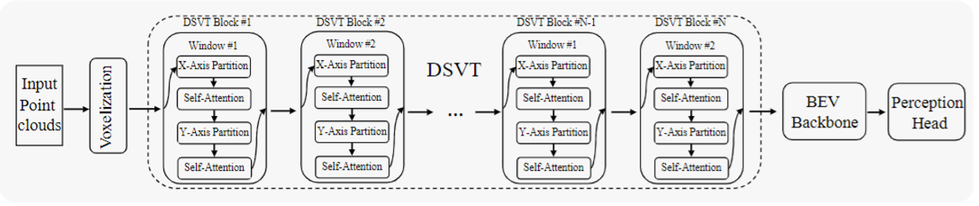
DSVTの概略 (参考文献 [1] より引用)
DSVT Blockの中では次のような操作が行われています。
まず、以下のように点群をボクセルに分割して、x方向に関してそれぞれ同サイズかつ非重複のサブセットに分けます。
このようにすることでself-attentionを並列処理することができ、より効率的な計算が可能になります。
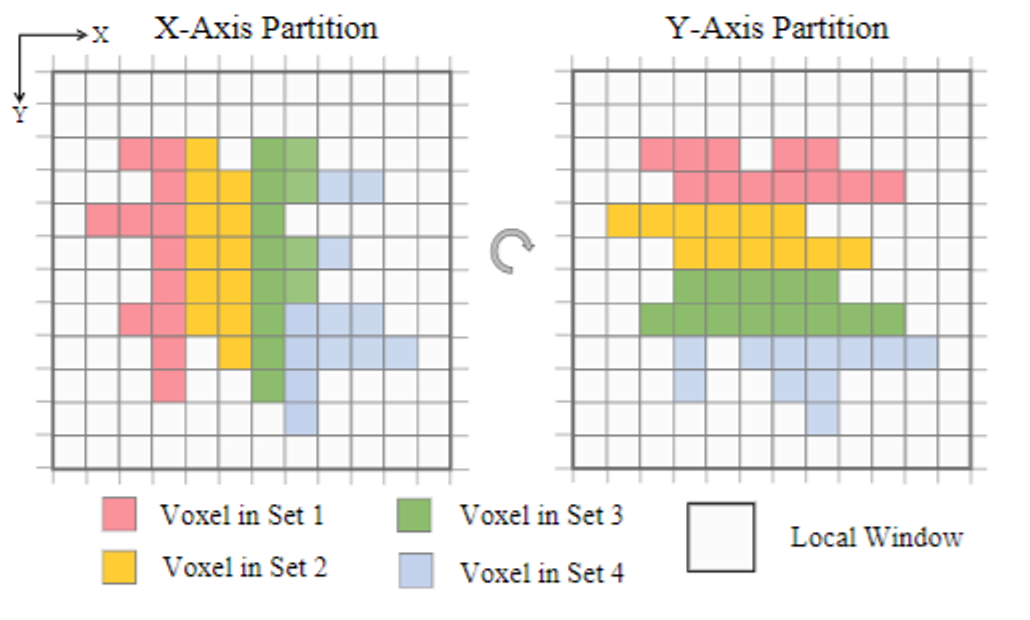
DSVT Blockでの操作 (参考文献 [1] より引用)
また、x軸方向でself-attentionを計算した後、y軸に関しても同様にself-attentionを計算します。
こうすることでサブセット間のつながりを強化することができます。
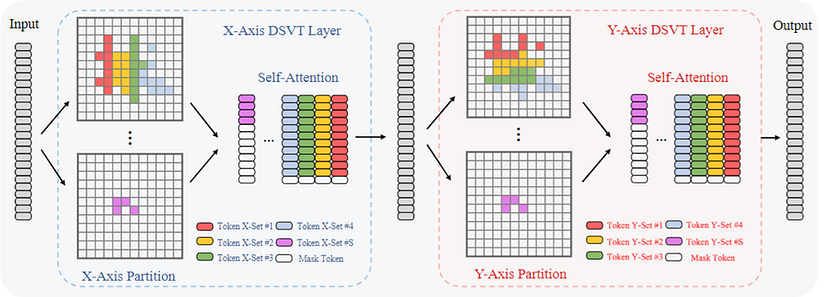
DSVT Blockの概略 (参考文献 [1] より引用)
そのような操作をまとめてDSVT Blockとし、それを複数回繰り返すことで物体の3次元特徴量を抽出しています。
以下の図はwaymoデータセットでのベンチマークの結果になります。(推論にはA100GPUを使用)
DSVTは既存手法 (CenterPoint-Pillar)に比べてmAPで9ポイントほど性能が向上していることがわかります。
また、推論速度に関してもTensorRT化したもので27Hz出ており、LiDARの周波数が10~20Hzであることを考えると、リアルタイム性には問題がないといえます。
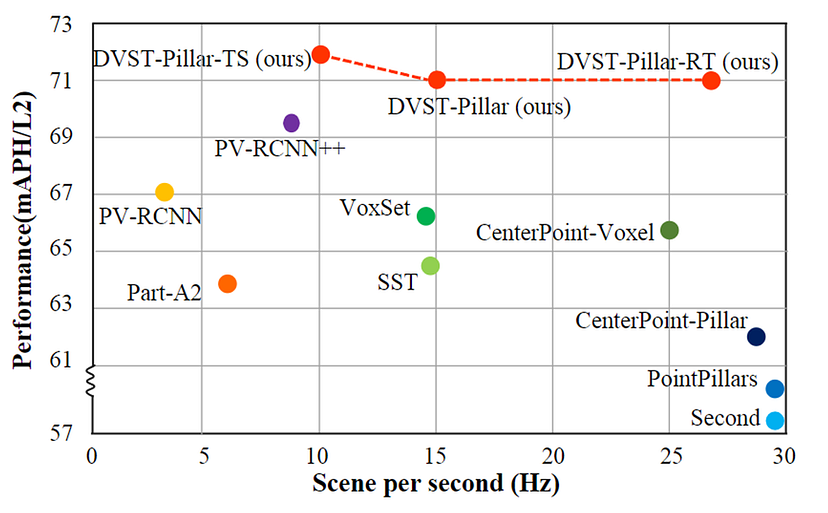
ベンチマーク結果 (参考文献 [1] より引用)
今回、このDSVTをティアフォーの機械学習フレームワークに実装し、現在使われているCenterpointとの比較を行いました。結果は以下の通りです。
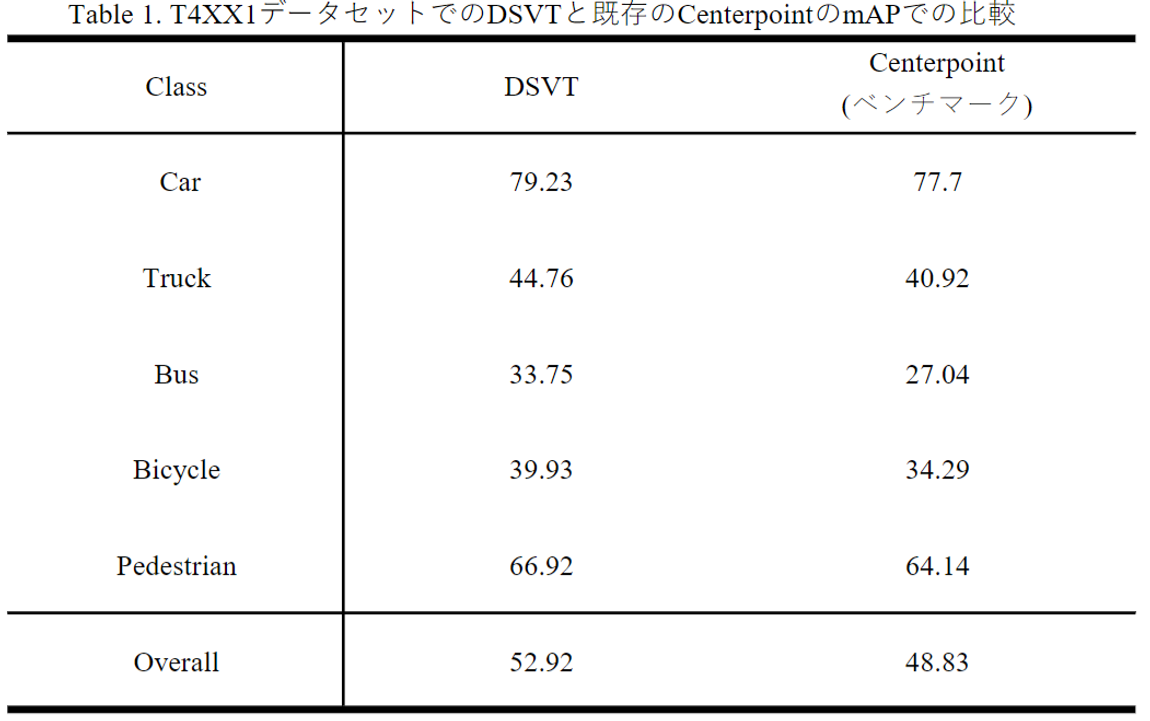
ティアフォーデータセット(T4XX1)を利用したDSVTブロック有無の評価
結果的に今回のDSVTはすべてのクラスにおいて既存のCenterpointを上回る性能を示しました。全体としてはmAPで4ポイント向上しています。既存のCenterPointは様々な工夫が施されているので、論文での主張に比べてポイントの向上は低いものの、精度面において大きな進歩であるといえます。
共同研究ではこのようにTransformerベースの物体検出についても実装に向けて研究と開発を行っています。
参考文献
[1] H. Wang, et al., “DSVT: Dynamic Sparse Voxel Transformer with Rotated Sets,” in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 2023 pp. 13520–13529.
おわりに
本記事では、2023年度のティアフォーと松尾研究所の取り組みの成果の一部を紹介しました。次回も引き続き昨年度の松尾研究所との取り組み結果について紹介していきます。
ティアフォーでは、「自動運転の民主化」というビジョンに共感を持ち、自らそれを実現する意欲に満ち溢れた新しい仲間を募集しています。
ティアフォーではAI関連の職種を多く採用をしています。詳細は、ティアフォーの「求人ページ」をご覧ください。
「どの職種で自分の経験を活かせるかが分からない」「希望する職種が見つからない」などの場合は、ぜひ「キャリア登録」をお願いします。
お問い合わせ先
- メディア取材やイベント登壇のご依頼:pr@tier4.jp
- ビジネスや協業のご相談:sales@tier4.jp
ソーシャルメディア
X (Japan/Global) | LinkedIn | Facebook | Instagram | YouTube
関連リンク