
自動運転における物体移動予測と行動計画への機械学習導入
ティアフォーと松尾研究所は、2020年から共同研究を開始し、2024年で5年目を迎えました。本共同研究では自動運転レベル5の実現を目指し、短期テーマと長期テーマという2つの時間軸で課題解決に取り組んでいます。
本記事は、2023年度の取り組み内容を報告する全3回のブログの2回目になります。1回目と2回目は短期テーマで取り組んだ課題とその問題解決のためのアプローチを、最後の1回は長期テーマに焦点を当てた方針と取り組みの一部を紹介します。短期テーマの取り組みを石橋英一郎さん・上田紘途さん・佐伯匡斗さん・髙田直輝さん・山下佳威さんのメンバーで報告し、本記事ではその概要の一部をお伝えします。
短期テーマでは、ティアフォーが開発を主導する自動運転用のオープンソースソフトウェア「Autoware」の機能改善に取り組んでいます。具体的には、松尾研究所が持つ深層学習に関する知見を活かし、自動運転の現場に近い立場から、「Autoware」が有するモジュールの認識精度や予測精度の改善などを進めています。
一方、長期テーマでは、松尾研究所が注力している世界モデルの自動運転領域への応用に取り組んでいます。世界モデルは、観測情報から実世界の変化を学習するモデルです。この技術を自動運転領域に応用することで、より高次な自動運転技術の実現に貢献できると考え、基礎研究的な立場から研究開発を進めています。
それぞれ研究開発の状況や、目標としている時間軸は異なりますが、将来的には各テーマが有機的に働き、本共同研究の最終目標の達成につながると信じています。
共同研究内容4:PredictionタスクにおけるDNNベースのSoTA手法
背景
Predictionタスクとは、自車両・他車両の過去軌道(各時刻での座標や速度など)や周辺の地図データを入力として、他車両の未来軌道を予測するタスクを指します。Predictionは、現在の「Autoware」ではPerceptionモジュールに内包されており、Detection部で検出した物体に対して、未来軌道を予測しています。予測した未来軌道は、Plannningコンポーネントに送られ、自車の行動計画や生成軌道のリスク評価に使用されます。 現在の「Autoware」においては、車両の運動力学に基づいたルールベースの手法でPredictionが実装されており、周囲車両の2~3秒程度の未来予測が可能になっています。ただし、より長時間の予測、複雑な道路状況、他車両との干渉が発生する状況での予測については精度が落ちてしまうため、これらを改善するPrediction手法が研究されています。特にDNN(Deep Neural Network)ベースの手法は、従来手法に比べて複雑な状況下や長時間の予測において非常に高い精度を示すため、注目されています。
概要
今回採用した手法はMTR(Motion TRansformer)という手法で、Waymo Open Dataset [1] のMotion Prediction Challangeにて初期版のMTR [2] が2022年のSoTAに、拡張版のMTR++ [3] が2023年のSoTAになっています。また、2024年にMTR v3 [4] という拡張版が発表されるなど、高い精度を示す手法が継続的に拡張されており、注目を集めています。初期版のMTRのアーキテクチャは以下のような(a)、(b)、(c)の3部分に分かれた構造になっています。まず、過去軌道データと地図データはベクトル表現で入力されます。その後、MLPで構築されたPolyline Encoderによって特徴ベクトルに変換され、系列データとしてTransformer Encoderに入力されます。Agent特徴は(a)に、Map特徴は(b)に入力され、特に(a)ではAgent間の相互作用が考慮された未来の軌道も含めた全軌道を出力します。既存の手法ではAgent間の相互作用については過去軌道での相互作用にのみ注目されていたことに対し、MTRではこのような構造により、予測した未来軌道でのAgent間の相互作用についても考慮されています。さらに、右折や直進などの異なる運動モードに対して、それぞれの意図のクエリ (Intention query)が導入されています。ここまでの結果を(c)のDecoderに入力し、反復的に洗練された未来軌道を出力します。
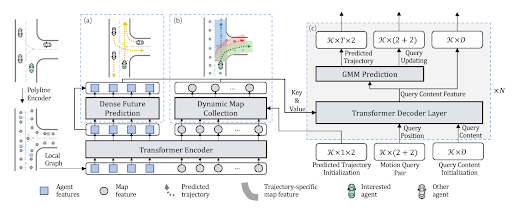
MTR(初期版)のアーキテクチャ [2]
拡張版であるMTR++においては、MTRではグローバル座標系で入力していた軌道を各車両の車両座標系とする変更が加えられました。これにより、それぞれのローカル座標系での他車両との関係をエンコードでき、複数の車両の同時推論が可能となり、大幅な推論速度の高速化を達成しています。
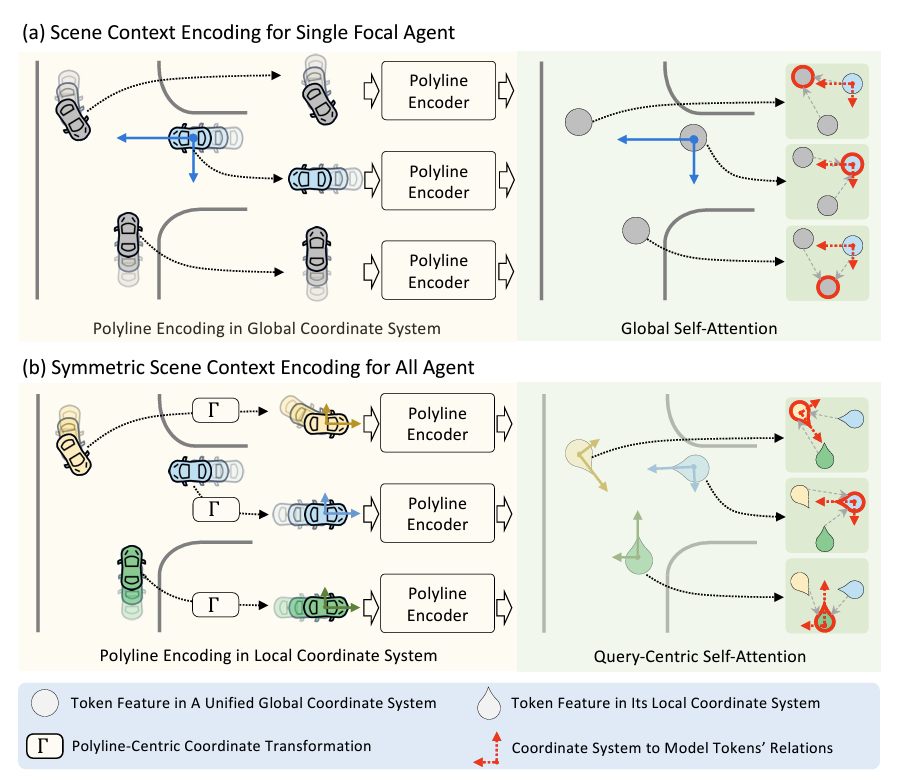
MTR++における改善点 [3]
結果
今回は、ティアフォ―の取得した実走行データに対し、初期版のMTRの推論を実行しました。図は可視化結果で、大幅な破綻は無く車両の軌道予測ができていることが確認できました。また、「Autoware」で取得したデータからMTRの入力データを不足なく作成できることを実証しました。松尾研究所では、更なる拡張手法などの最先端の手法を取り入れたPredictionモジュールの開発に引き続き取り組んでいきます。
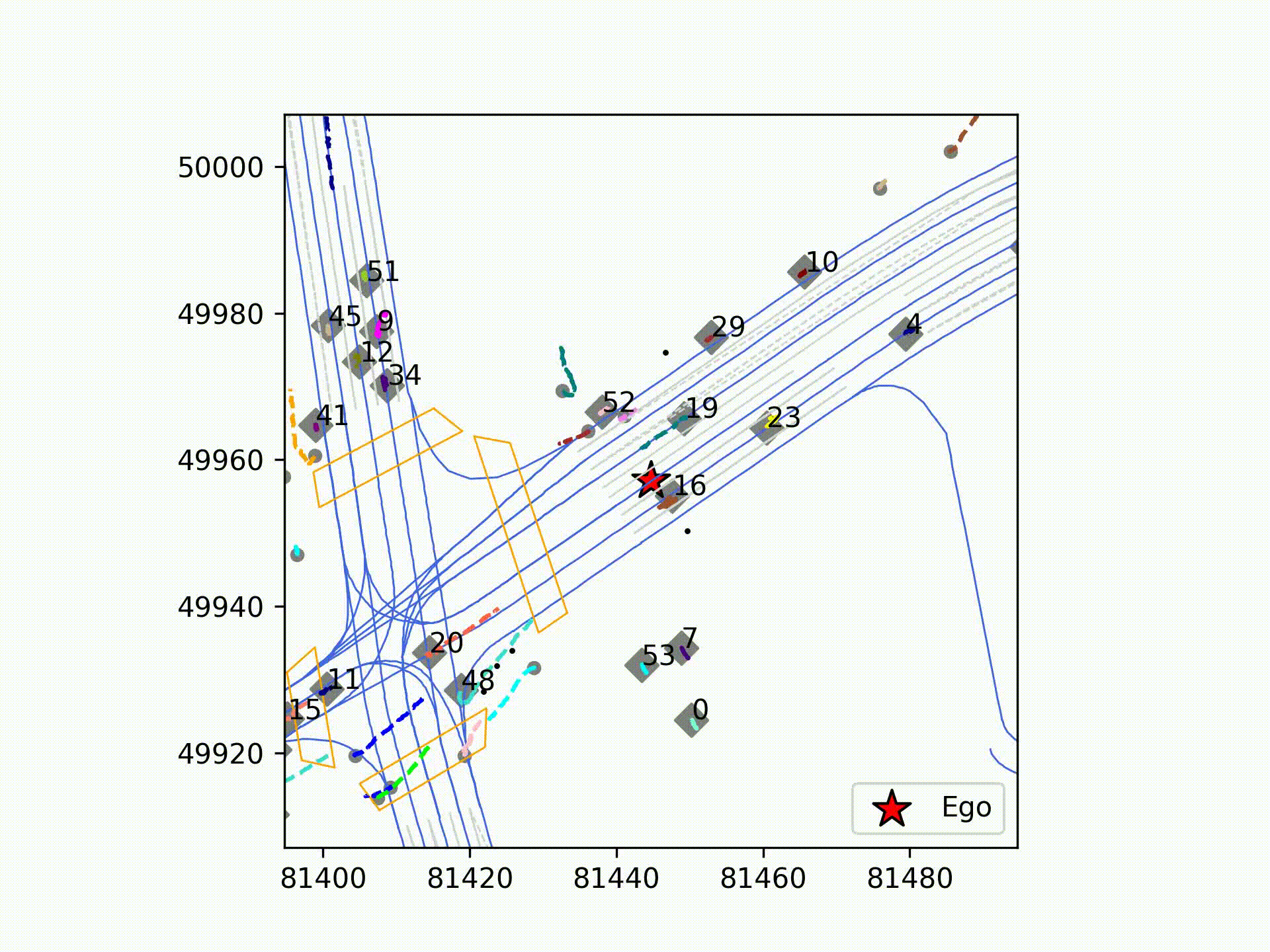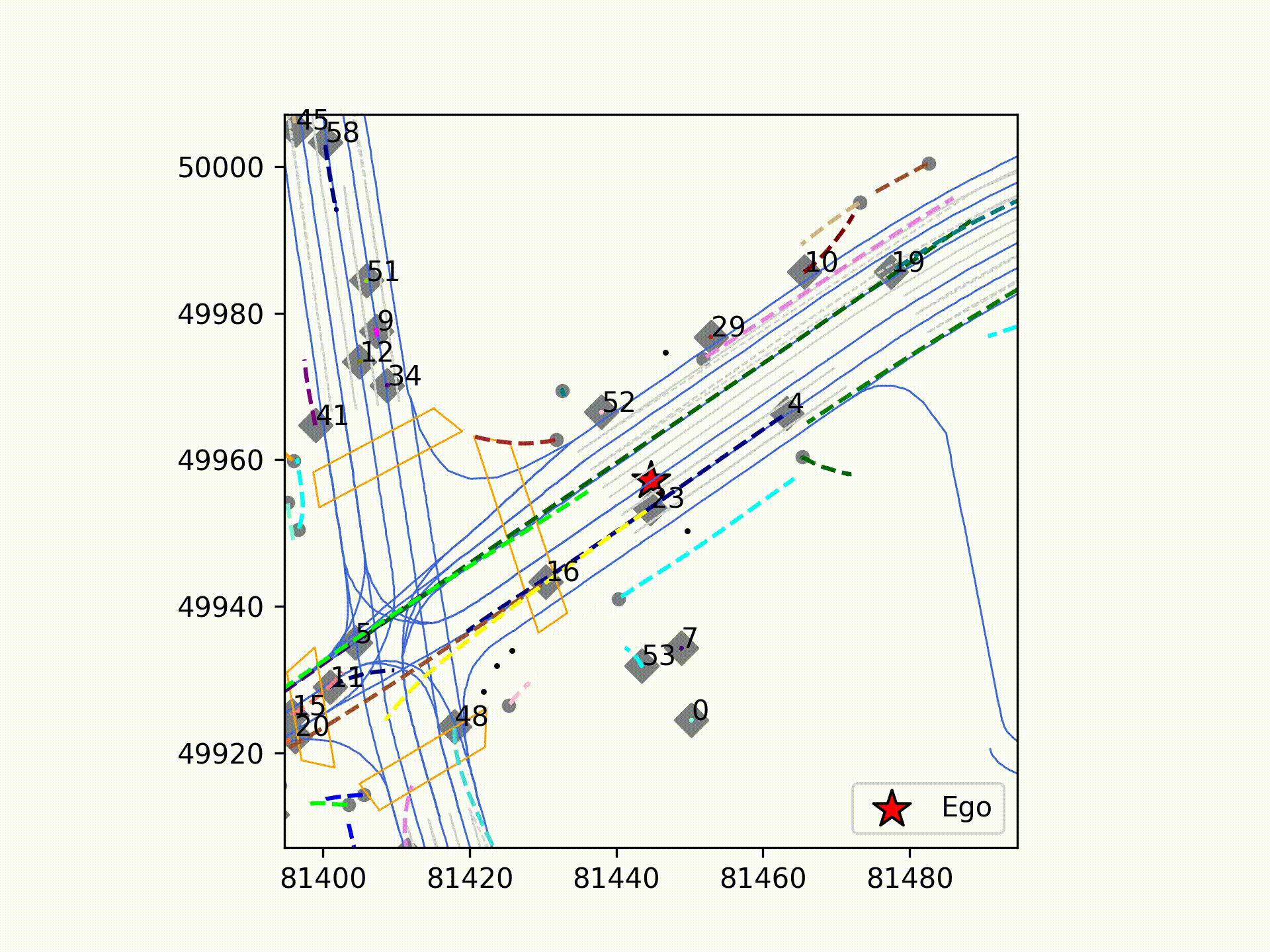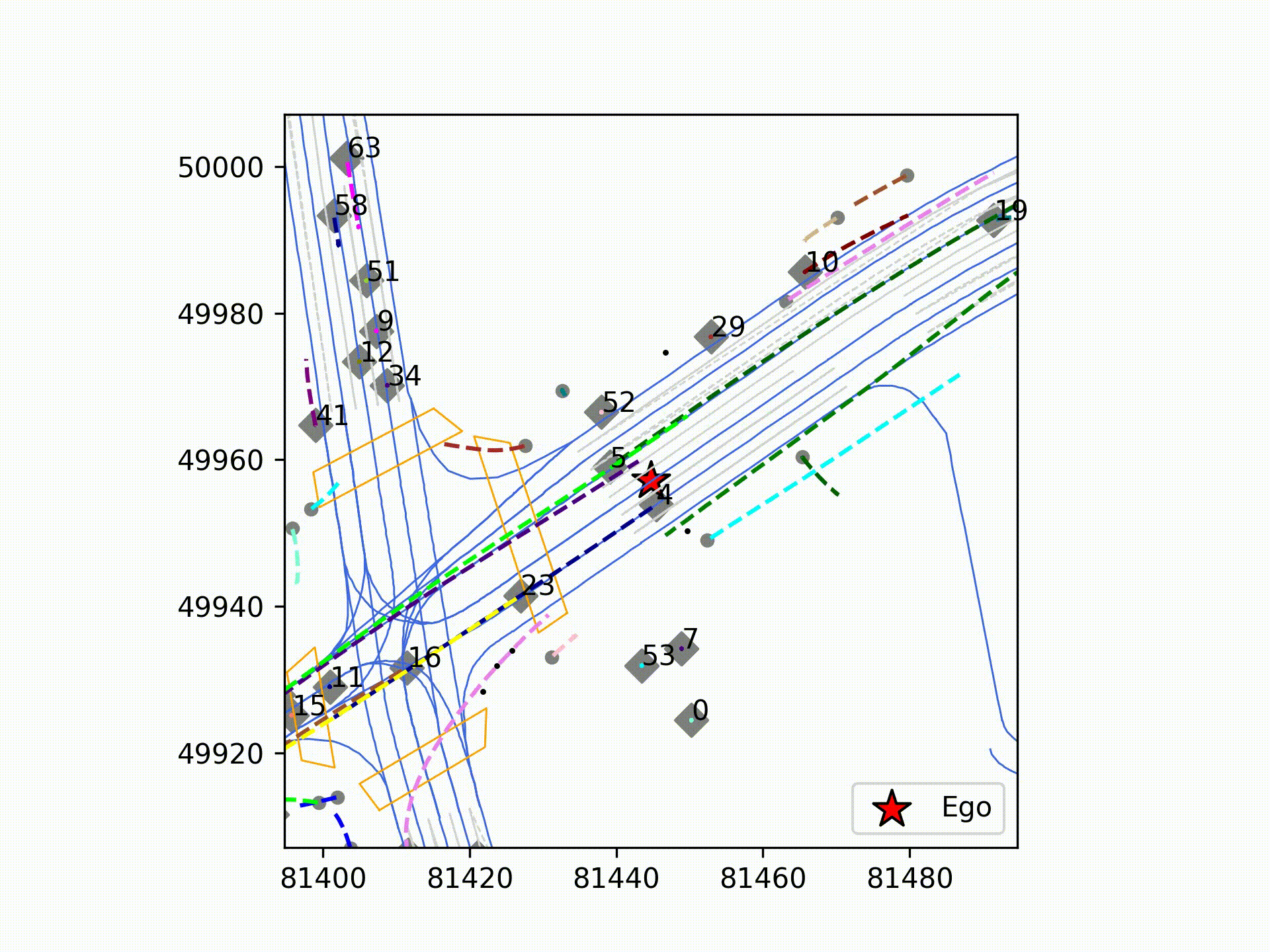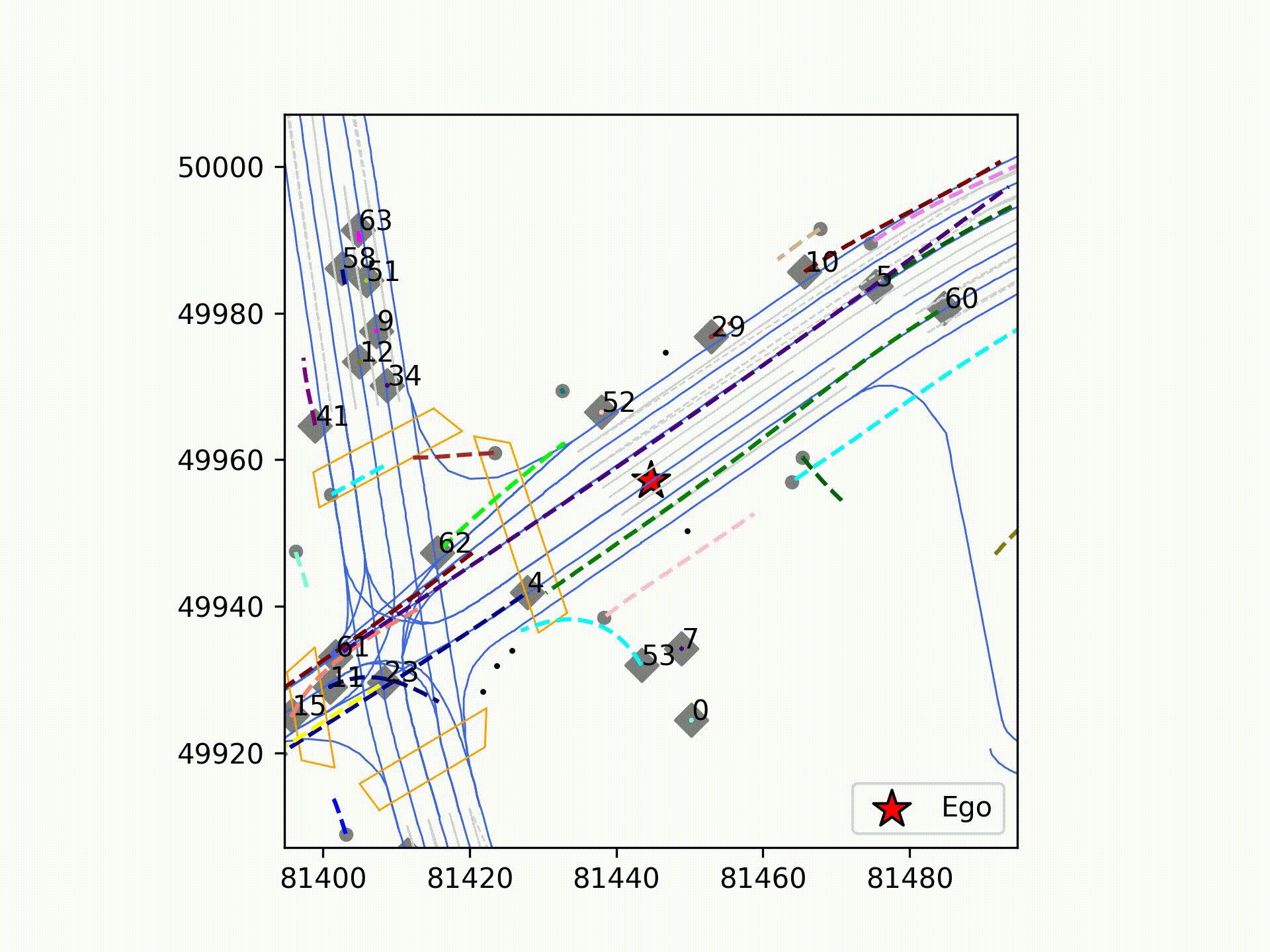
ティアフォーのデータセットで学習し、お台場環境で推論
参考文献
[1] S. Ettinger, et al., “Large Scale Interactive Motion Forecasting for Autonomous Driving: The Waymo Open Motion Dataset”, ICCV2021.
[2] S. Shi, et al., “Motion transformer with global intention localization and local movement refinement“, NeurIPS 2022.
[3] S. Shi, et al., “MTR++: Multi-Agent Motion Prediction with Symmetric Scene Modeling and Guided Intention Querying“, arxiv preprint https://arxiv.org/abs/2306.17770
[4] N. Shi, et al., “MTRv3: 1st Place Solution for 2024 Waymo Open Dataset Challenge- Motion Prediction“, 2024 WOD Motion Prediction Challenge Technical Reports. https://storage.googleapis.com/waymo-uploads/files/research/2024 Technical Reports/2024 WOD Motion Prediction Challenge - 1st Place - MTR v3.pdf
共同研究内容5:NPC行動の改善
「AWSIM」とは、自動運転OSの「Autoware」をEnd to Endでシミュレーションできる、デジタルツイン指向のオープンソース自動運転シミュレーターです。「AWSIM」はゲームエンジンの一種であるUnityで作成されています。シミュレーター内は実際の道路環境を模しており、車両や歩行者の交通流、信号などが再現されています。実機と同じ枠組み(ROS2)で、「Autoware」と通信を行うことができるため、簡単に「Autoware」の各コンポーネントをテストすることができます。
「AWSIM」の環境内では、多数のNPC(Non Player Character)車両が走行しており、その制御は、現状Unityのスクリプトによって行われています。自動運転のシミュレーターとして「AWSIM」を用いる場合、NPC車両の行動パターンは、現実世界で人間が運転する車両と同レベルの行動を再現することが求められます。
行動改善を実現するにあたり、模倣学習による手法と、行動予測技術による手法の2種類の方向性から取り組んでいます。
模倣学習によるNPC行動の改善
人間の運転行動を再現するため、まず模倣学習ベースの手法を採択しました。観測をもとに行動を決定する方策を学習する点は強化学習と同様ですが、強化学習が予め設計された報酬関数に基づく報酬の割引和を最大化する方向に学習するのに対し、模倣学習は「専門家」の振る舞いを模倣する方向に学習します。
模倣学習では、まず初めに模倣対象となる「専門家」がタスクを実行する様子をビデオで録画したり、センサー情報を収集したりして、デモンストレーションデータを獲得します。今回の自動運転においては、人間が車両を運転する際の環境情報と運転コマンドを収集しました。その次に、デモンストレーションデータをもとに、方策がその行動パターンを模倣できるように機械学習による最適化を行います。
模倣学習における方策学習のアルゴリズムでは、すでに様々な手法が提唱されていますが、今回はGAIL(Generative Adversarial Imitation Learning)[1] を用いました。GAILの概要を簡単に説明すると、模倣学習の枠組みを、GAN(Generative Adversarial Network) を用いて行う仕組みです。すなわち、Discriminatorネットワークでは、デモンストレーションデータと方策ネットワークから出力される行動を見分けられるように、Generatorネットワークでは、Discriminatorに自らの出力する行動をデモンストレーションデータのものだと誤認識させられるように学習を行います。
模倣学習や強化学習など、方策学習で高いパフォーマンスを達成するためには、ネットワークへの入力となる観測情報をどのような情報で構成すべきかが重要です。
模倣学習による方策学習は、ある一定の性能に達するまで試行錯誤を要します。
松尾研究所では引き続き、模倣学習による人間らしい運転行動の再現を目指していきます。
行動予測技術(Prediction)によるNPC行動の改善
人間の運転行動を再現するにあたり、模倣学習以外にも、行動予測技術を用いることが考えられます。Prediction Modelは主に自動運転の分野で研究が行われており、車両や歩行者といった行動主体の行動や移動経路を予測することができます。このように他の車両や歩行者の行動が予測できれば、安全に自車両の行動を決定できるため、安全な自動運転技術の確立のために近年注目を集めています。
今回は、前章でも述べたMTR(Motion TRansformer)を採択しました。松尾研究所では、このPrediction Moduleを用いて、「AWSIM」上のNPC車両の予測行動を生成し、その軌跡を適用することで、データドリブンでより人間に近い運転行動の生成に取り組んでいます。
参考文献
[1] J. Ho, et al., “Generative Adversarial Imitation Learning”, CoRR2016.
[2] S. Shi, et al., “Motion transformer with global intention localization and local movement refinement“, NeurIPS 2022.
[3] S. Shi, et al., “MTR++: Multi-Agent Motion Prediction with Symmetric Scene Modeling and Guided Intention Querying“, arxiv preprint https://arxiv.org/abs/2306.17770
[4] S. Ettinger, et al., “Large Scale Interactive Motion Forecasting for Autonomous Driving: The Waymo Open Motion Dataset“, ICCV 2021.
共同研究内容6:Planningモジュールが生成した軌道の逆強化学習によるスコアリング
背景
現状の「Autoware」のPlanningモジュールは、Lane driving、Parkingなどの特定のシナリオに沿った軌道を生成する構造となっており、複数シナリオが絡み合った軌道を出力することが難しくなっています。これに対し、各国の自動運転企業が開発しているPlanningモジュールの中には、状況に応じて軌道を多数生成(サンプル)し、生成軌道から目的・条件に合う軌道を選択する、軌道生成部分(サンプラ)と軌道選択部分(セレクタ)を組み合わせた構造となっているものがあります。この構造の利点は複数のシナリオが絡み合う複雑な軌道の出力が可能です [1] 。
さらに、サンプラとセレクタの双方においてデータ駆動型の手法を取り入れやすいことと、2022年にnuPlan [2] というPlanning用の大規模データセットが公開されたこともあり、機械学習手法を取り入れたサンプラ・セレクタの研究が注目されています。
概要
今回は軌道選択モデルに特に着目してサーベイを行った結果、Drive IRL [3] という手法があり、こちらは逆強化学習手法によって構築した軌道選択モデルです。強化学習では、環境の観測データを基に行動し、行動後の環境の観測データから計算された報酬の将来にわたる割引和の期待値を最大化するよう、行動方策を更新します。これに対し逆強化学習では、観測データとエキスパートの行動の履歴から報酬関数を推定します。すなわち、逆強化学習において、人間の運転データをエキスパートの行動履歴として導入することで、人間が運転においてどのような報酬関数を用いているのかを推定することが可能です。運転における報酬関数が獲得できれば、それに基づいて軌道の適切さをスコアリングすることが可能となり、軌道選択モデルの実現に貢献できます。
松尾研究所ではティアフォ―と共同で、ティアフォ―の取得した国内データセットを用いて、データ駆動型の軌道選択モデルの実現に取り組んでいます。
参考文献
[1] https://github.com/orgs/autowarefoundation/discussions/5033
[2] H. Caesar, et al., “NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles“ , CVPR 2021, ADP3 workshop., https://www.nuscenes.org/nuplan
[3] T. Phan-Minh, et al., “DriveIRL: Drive in Real Life with Inverse Reinforcement Learning”, ICRA 2023.
おわりに
本記事では、2023年度のティアフォーと松尾研究所の取り組みの成果の一部を紹介しました。次回も引き続き、昨年度の松尾研究所との取り組み結果について紹介していきます。
第1回の記事はこちら。
ティアフォーでは、「自動運転の民主化」というビジョンに共感を持ち、自らそれを実現する意欲に満ち溢れた新しい仲間を募集しています。
ティアフォーではAI関連の職種を多く採用をしています。詳細は、ティアフォーの「求人ページ」をご覧ください。
「どの職種で自分の経験を活かせるかが分からない」「希望する職種が見つからない」などの場合は、ぜひ「キャリア登録」をお願いします。
お問い合わせ先
- メディア取材やイベント登壇のご依頼:pr@tier4.jp
- ビジネスや協業のご相談:sales@tier4.jp
ソーシャルメディア
X (Japan/Global) | LinkedIn | Facebook | Instagram | YouTube
関連リンク