
ニューラルシミュレーターとマルチモーダル世界モデル
ティアフォーと松尾研究所は、2020年から共同研究を開始し、2024年で5年目を迎えました。本共同研究では自動運転レベル5の実現を目指し、短期テーマと長期テーマという2つの時間軸で課題解決に取り組んでいます。
本記事は、2023年度の取り組み内容を報告する全3回のブログの最終回です。1回目と2回目は短期テーマで取り組んだ課題とその問題解決のためのアプローチを紹介しました。3回目となる今回は、長期テーマに焦点を当てた取り組みを坂本滉也さんと峰岸剛基さんのメンバーで報告します。
ティアフォーでは、本テーマを通して、松尾研究所が注力している「世界モデル」の自動運転分野への応用を目指しています。世界モデルは、観測された情報に基づいて世界の構造を学習するモデルです。自己教師あり学習を通じ、空間的・時間的にコンパクトな「潜在表現」を獲得します。これにより、環境や状況など世界の刺激を効率的に表現できるのが特徴です。
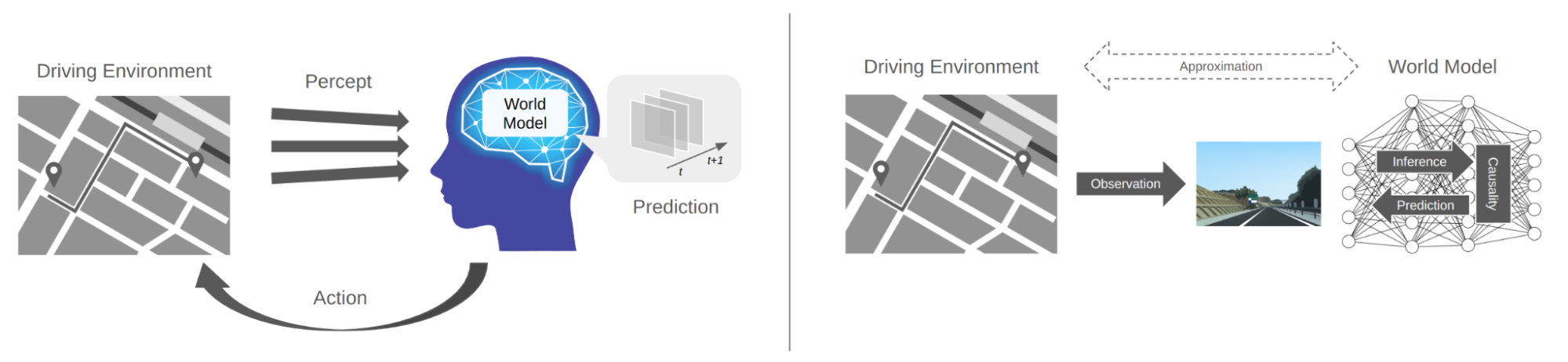
世界モデルの概要
今回のプロジェクトでは、世界モデルの自動運転への応用について以下の2つの取り組みに焦点を当てました。
1つ目は、世界モデルの要素技術として、Neural Radiance Fields(NeRF)ベースのニューラルシミュレーターの開発です。NeRFの登場により3次元再構成が精巧になっていくにつれ、自動運転ドメインでの再構成手法も盛んに研究されるようになりました。本研究では、センサシミュレーション単体での精度評価に加え、自動運転における3次元物体認識タスクを通じた評価も行い、自動運転シミュレーターとして用いられるかの検証を行いました。
2つ目は、データの再構成だけでなく、任意のシーンを生成するためのマルチモーダル世界モデルの構築です。具体的には、アクション、カメラ画像、テキスト、ポイントクラウド、高精度3次元地図(HDマップ)などの時系列情報を、自己教師あり学習(未来予測)を通じて世界の構造を学習する世界モデルを目指しています。今回は、主にシミュレーター空間における初期的な検証を行いました。
共同研究内容7:ニューラルシミュレーター
背景
自動運転技術の安全性の評価は、走行環境を模擬したシミュレーションが一般的になってきています。しかしながら、評価のためのシミュレーション環境を人手で作成する必要があり、時間的にも金銭的にも膨大なコストがかかってしまいます。これらのコストを削減しつつ現実に近いシミュレーションを実現する方法として、データ駆動型のシーン再構成技術が注目されています。
特に深層学習を用いたNeRFは3次元空間におけるカメラの位置姿勢と3次元座標を入力としてRGB値と物体が存在するかを表すDensity(密度)を出力するモデルであり、その3次元再構成精度の高さから有望な技術とされています。本共同研究では、データ駆動型のシミュレーションを実現するためにNeRFにいち早く注目し、先行的に研究開発を行ってきました。
NeRFによる自動運転走行シーン再構成
画像から3次元再構成を目指す手法としてNeRFが提案されました。NeRFは新視点画像生成タスクにおいて2020年にSoTAを達成したことで知られています。NeRF技術の応用による自動運転のセンサーシミュレーション高精度化が期待される一方で、広大な空間における写実性や3次元の幾何学的精度が課題でした。しかし、2022年に実データの学習によって大規模な都市環境を3次元合成するBlock-NeRF [Matthew Tancik+ ,CVPR 2022] が提案され、NeRFによって写実性が高く大規模なシーン再構成ができることが示されました。
さらに、センサーシミュレーションにおける3次元幾何精度の向上についても、LiDARの3次元計測センサーで収集したデータを教師データとして、深度情報をより学習しやすくしたUrban Radiance Fields [Konstantinos Rematas+, CVPR 2022] や符号付き距離関数(Signed Distance Function:SDF)を考慮した手法であるUniSim [Ze Yang+, CVPR 2023] などが提案され、実データの学習によるシミュレーターの構築が現実的になってきています。
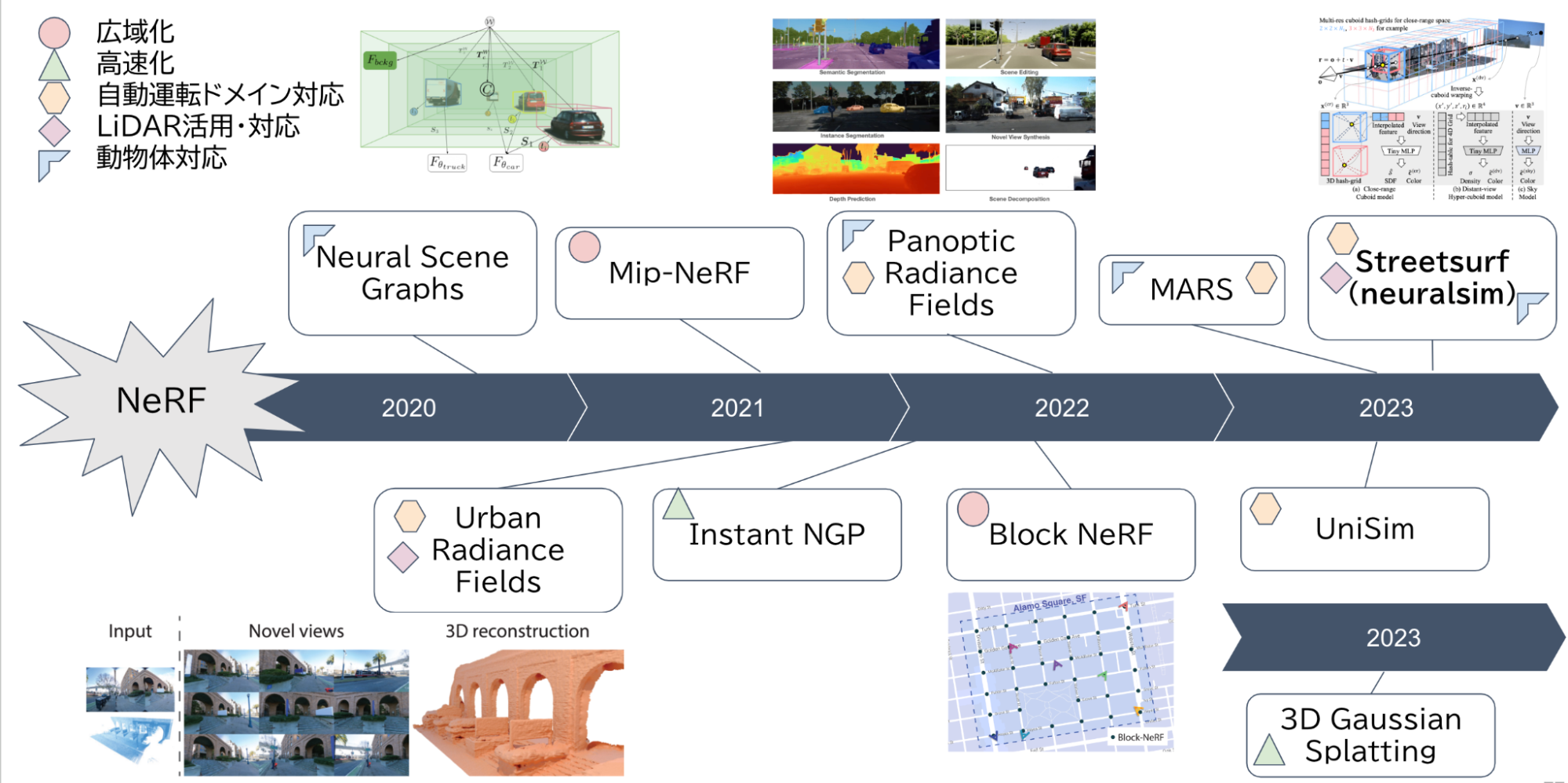
NeRFの自動運転走行シーン適用における研究動向
本年度の実施内容
このようにNeRFやSDFを用いた自動運転ドメインでの研究は近年盛んに行われている一方、それらの手法の評価方法はセンサー出力の再構成精度と正解データの比較にとどまっています。そのためシミュレーターを実際の自動運転システム評価で用いるためには、実際に自動運転システムで使われる物体検出アルゴリズムなどが出力されたセンサー上で適切に動作するか検証しなければいけません。
そこで本共同研究では、StreetSurf [Jianfei Guo+, arXiv:2306.04988] と呼ばれる手法に着目し、本年度はその実用性について検証を行いました。StreetSurfは走行シーンをNeuS [Peng Wang+, NeurIPS 2021](SDFにvolume renderingを用いられるようにすることでより高精細に表面形状を再構成可能とした手法)とNeRFで距離に応じて複数のモデルを利用する手法であり、他の既存手法と比べて再構成の精度が高いことが報告されています。
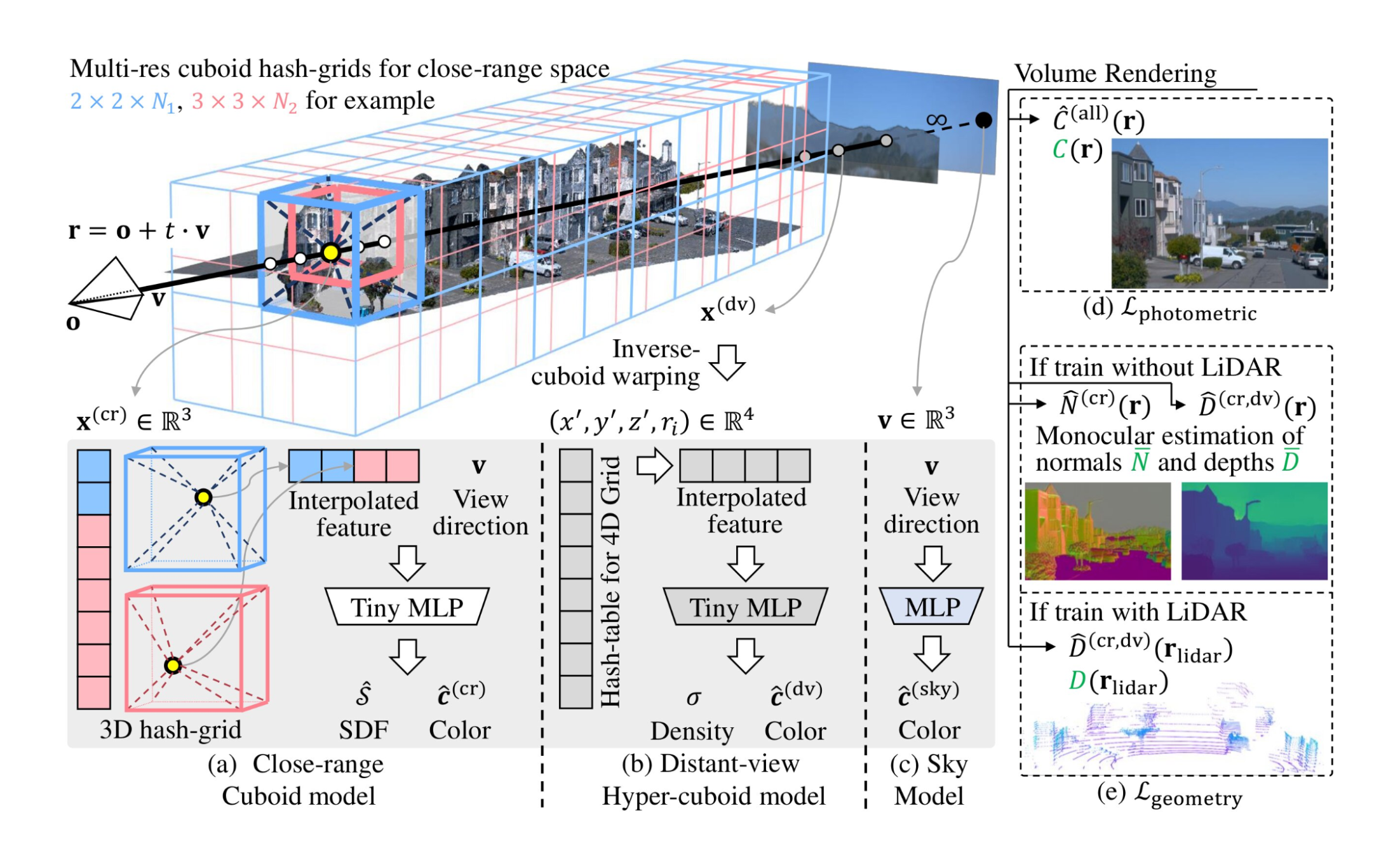
StreetSurf [Jianfei Guo+, arXiv:2306.04988]
また、StreetSurfの実用性の検証方法として、センサーレベルでの再構成誤差の評価に加え、3次元物体検出タスクを通じた再構成評価も行いました。
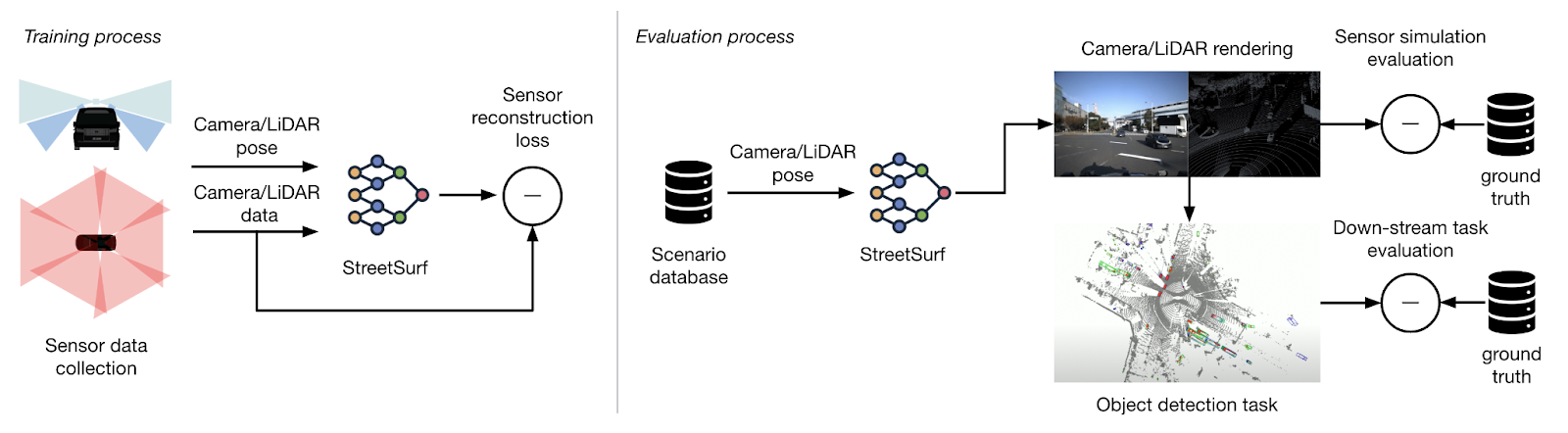
Neural Simulator の構成と学習評価のプロセス
センサーレベルにおける再構成評価
まずセンサーレベルにおける再構成の評価のため、3種類の車両の軌道におけるセンサーの再構成を行いました。
具体的には以下の通りです。
1) replay:学習軌道における再構成
2) nvs:新規軌道による再構成
3) nvs ∩ replay:新規軌道のうち学習軌道と重なっている部分での再構成
カメラ画像の再構成指標としてPeak Signal-to-Noise Ratio(PSNR)とStructural Similarity Index Measure(SSIM)、LiDARの再構成指標にはChamfer Distance(CD)を採用しました。評価結果を以下に示します。
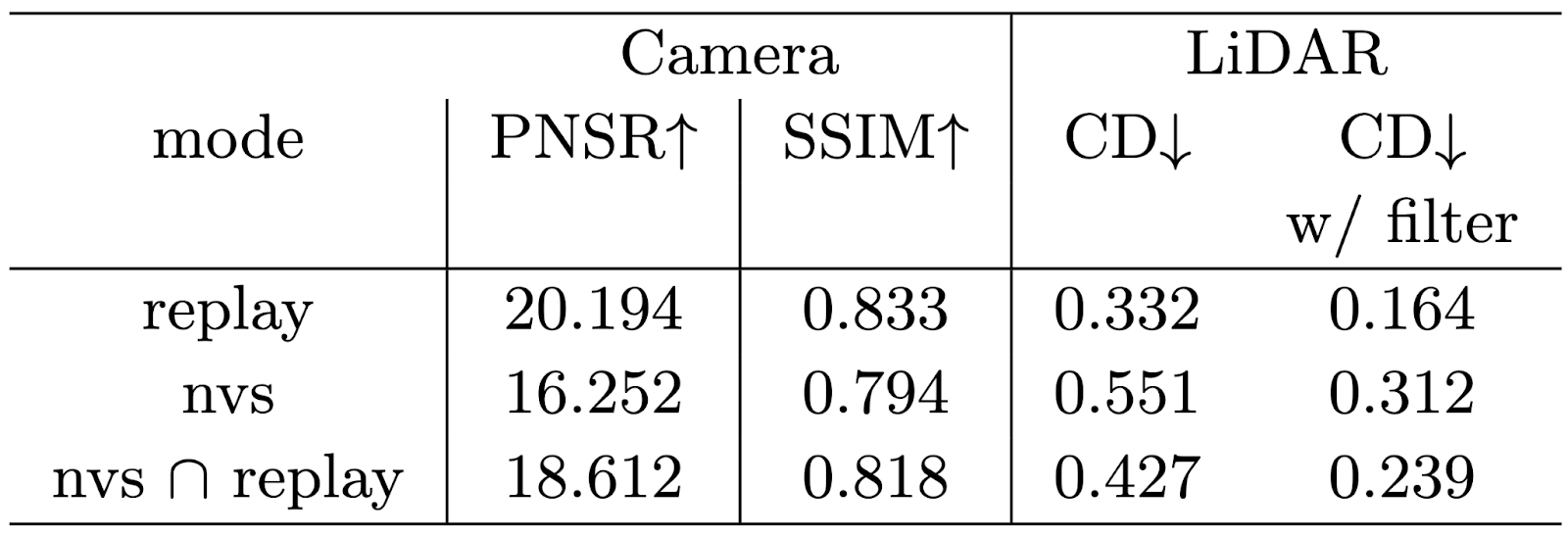
カメラ画像およびLiDAR点群の再構成精度

カメラ画像の再構成結果
LiDAR点群の再構成結果
カメラ画像の再構成精度については、replayと比較してnvsにおいてPSNRが著しく低下しています。この原因として、学習データから離れた地点での軌道も推論の対象に含まれている(外挿)ことが考えられます。実際、replay軌道の範囲に評価対象を限定した場合、nvs ∩ replayの結果ではnvsよりも精度が大きく向上します。したがって、カメラ画像再構成においては、外挿シーンに対しての再構成精度を保つのが困難であり、視点の重複が起こるようにデータを収集することが重要であるといえます。
点群については、nvs軌道のような外挿シーンであっても、replayに対しての精度劣化は限定的です。このことは、StreetSurf自体が表面形状に制約を持たせたSDFを利用しているため、外挿に対しても3次元形状はロバストになっていると考えられます。
3次元物体検出タスクにおける評価
次にStreetSurfによって再構成した背景点群による3次元物体検出タスクの性能への影響を検証しました。ただし、今回の検証ではStreetSurfは背景のみ対応しているため、動物体点群について再構成できません。そのため、動物体についてはGround truth点群から抽出して再合成し、3次元物体検出タスクへの入力とします。

3次元物体検出タスクにおける評価構成
3次元物体検出の結果を以下に示します。Ground truth点群とシミュレーション点群をそれぞれ入力とした場合の3次元物体検出の出力結果として、自車の近くかつ道路内では特に近い応答をしていることが分かります。自車両から遠くかつ道路外では異なった応答が見られ、これは点群数が少ない状況で、再構成誤差の影響が大きいためと考えられます。
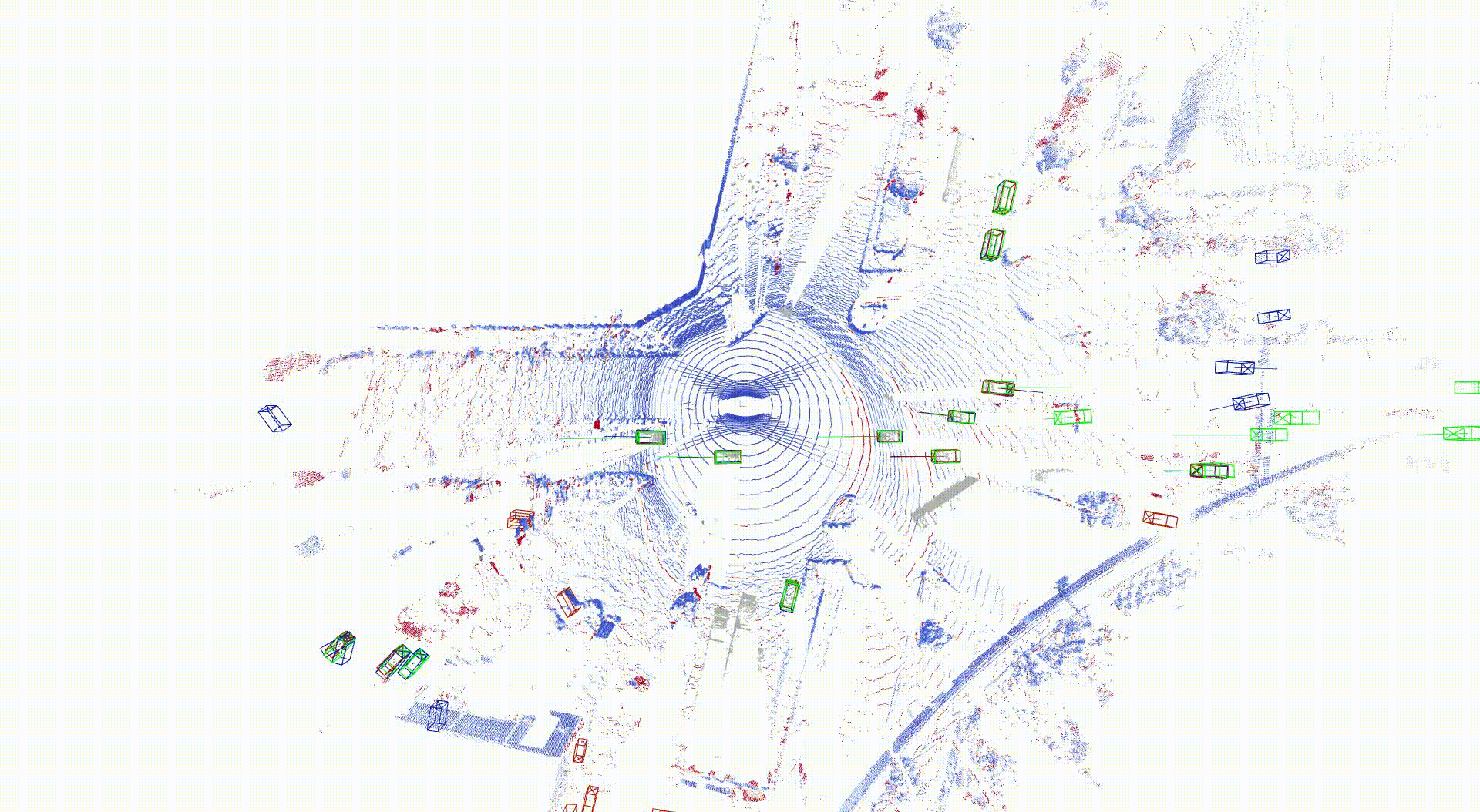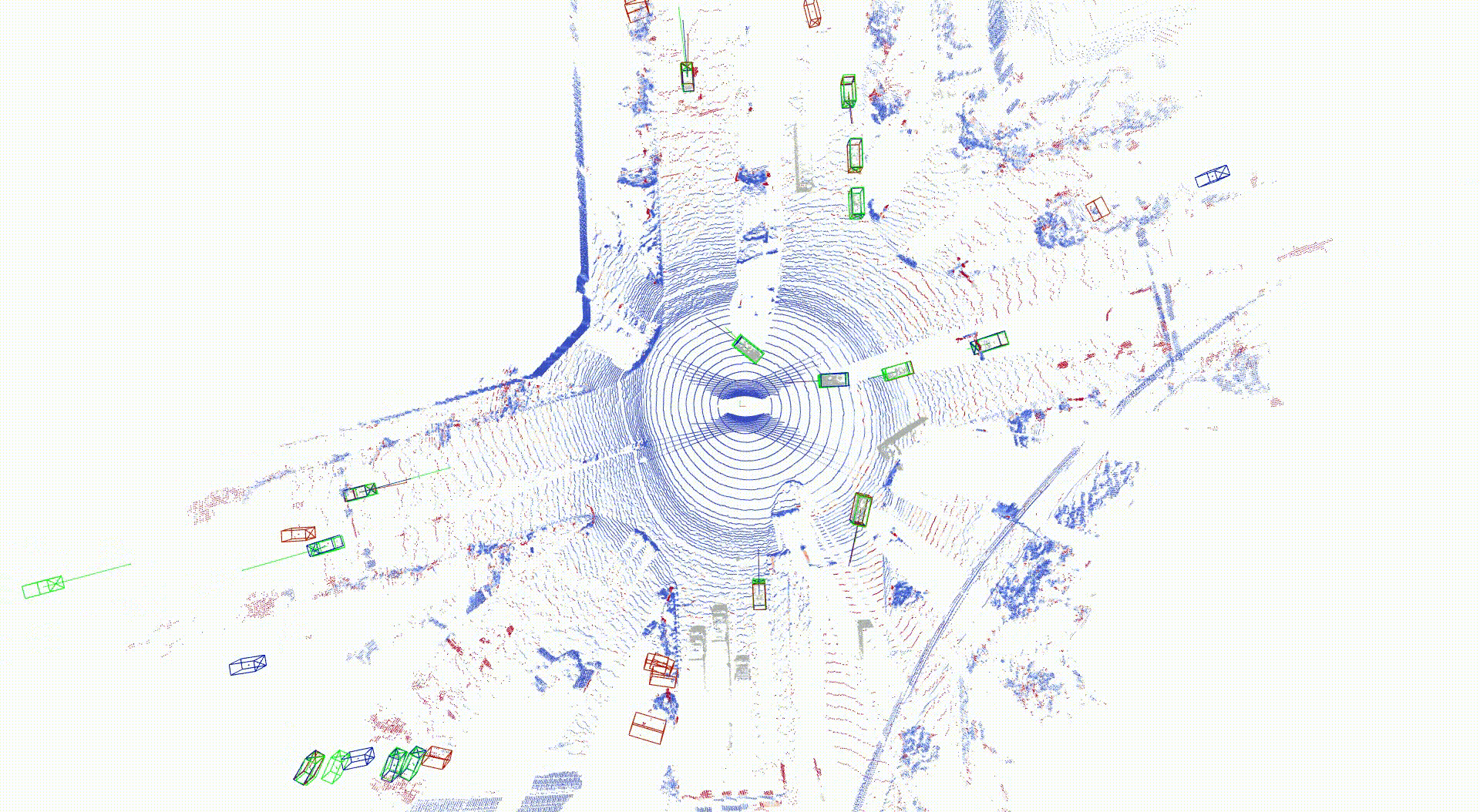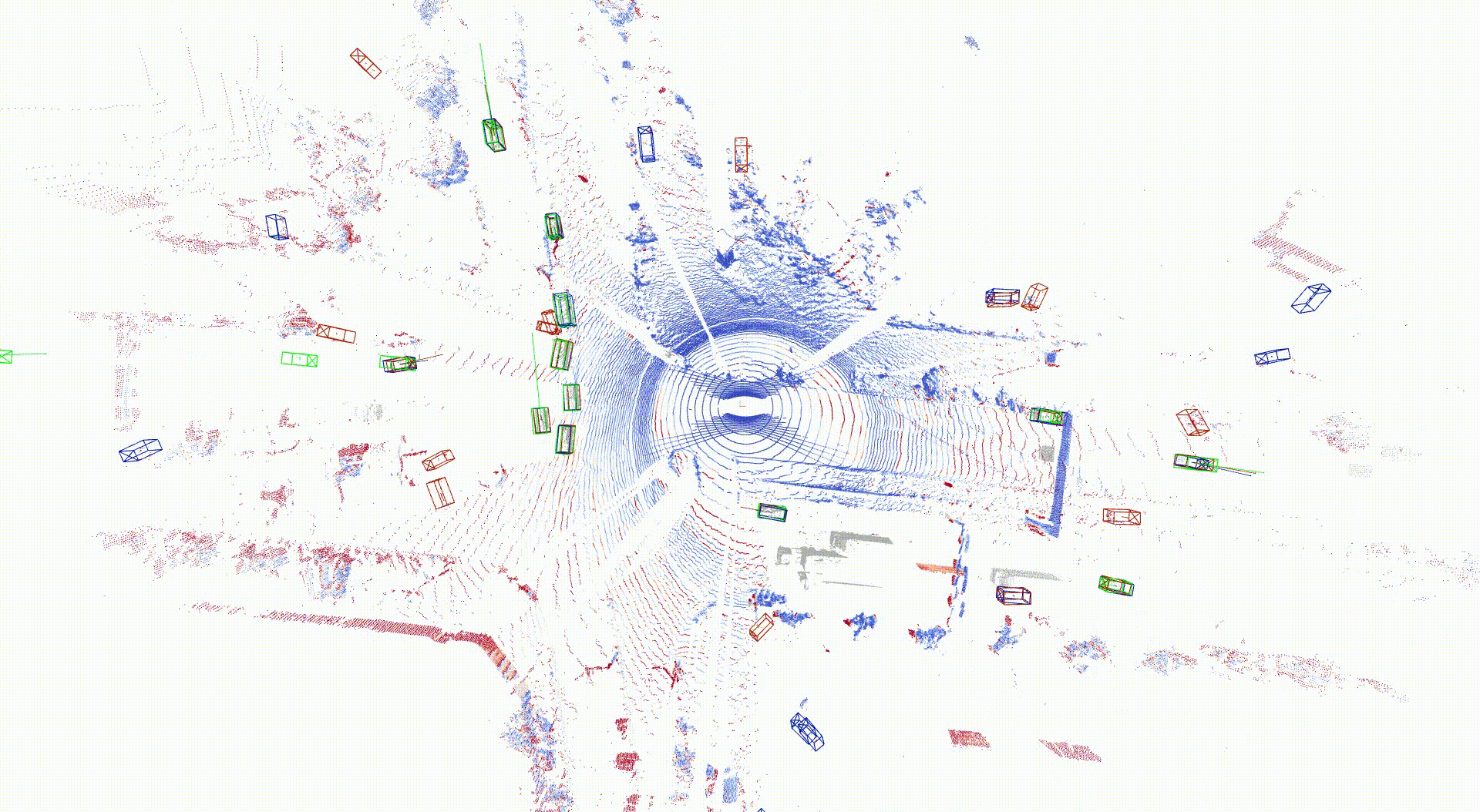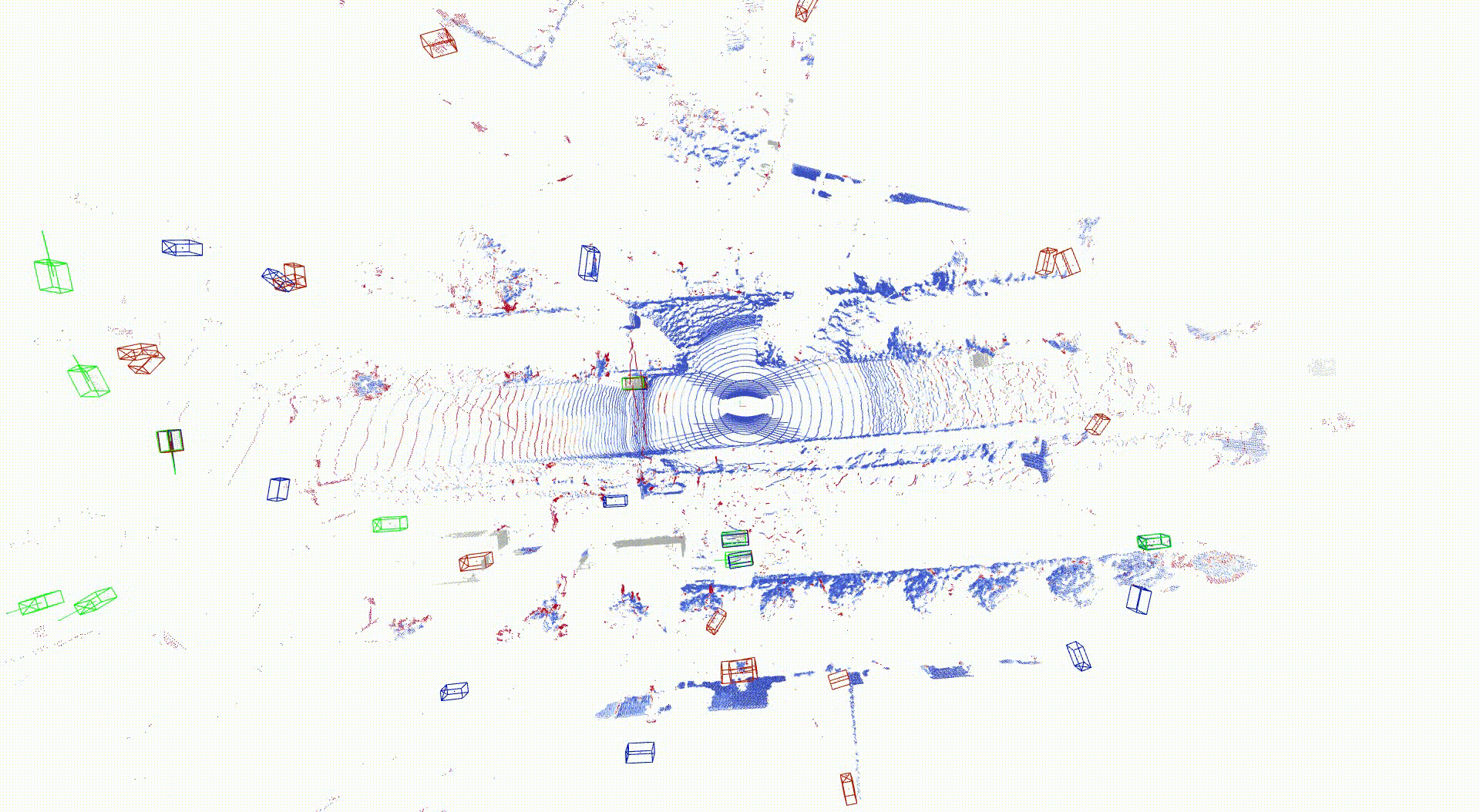
LiDAR 点群の再構成結果および物体検出タスク結果
点群色: Chamfer distance, Bounding box: アノテーション(緑)、 Ground truth点群入力結果(青)、シミュレーション点群入力結果(赤)
今回の検証の結果、カメラ・LiDARのセンサーシミュレーションにおいて、Neural Simulatorの有用性を確かめることができました。なお、本研究はJSAI 2024で「自動運転システムのためのNeural Simulatorの構築および評価」というタイトルで投稿し、発表を行いました。
今後の展望
本記事の内容は2023年時点の結果であり、背景のみの再構成評価について述べました。現在では動物体を含めたシーンの再構成や、都市環境のような大規模シーンの再構成についても取り組んでおり、その適用範囲の拡大に日々取り組んでいます。

お台場一帯でのシーン大規模化例
共同研究内容8:マルチモーダル世界モデル
想像上の世界を作り出す世界モデル
最先端の世界モデルは、既知の状況を再現するだけでなく、訓練データから外挿した未知のシーンや状況を生成することも可能です。この能力は、シミュレーションにおいて特に重要であり、実際の学習データに含まれる道路環境を超えたテスト(シーンの生成)を行うことができます。また、上記のような世界モデルの特性から強化学習タスクで使われることが多く、自動運転システムにおいても、行動学習のサンプリング効率の向上や、プランニングにおける「もしも」の思考実験への活用が期待されています。
このように世界モデルを自動運転領域に取り入れることによる利点が様々にあるため、2021年あたりから少しずつ自動運転領域での事例が見られるようになりました。

自動運転領域における世界モデルの効用
世界モデル研究の自動運転応用動向
2023年に入り、世界モデルの自動運転への導入事例が急増しています。イギリスの自動運転向けAI技術を開発するスタートアップであるWayveが2023年6月に発表したGAIA-1や、カナダのスタートアップであるWaabiが発表したCopilot4Dが代表的な世界モデル研究です。この急増の背景には、上述の世界モデルによる利点だけでなく、大規模言語モデル(Large Language Models:LLM)や生成AIといった深層学習の革新的技術の登場があります。
LLMは、大量のテキストデータから文脈関係を自己教師あり学習によって獲得し、それを活用して様々な文章を生成する能力を持っています。このようなLLMが登場できた技術の重要な要素は大量のデータを学習可能にした自己教師あり学習とTransformerというアーキテクチャです。この2つを自動運転領域で既にあった大量のセンサーデータに適用することで、世界モデルの現実世界への応用が可能になってきました。
世界モデルはLLMが言語空間で行なっていたことを現実世界に応用したものと考えることができます。つまり世界モデルも同様に大量のセンサーデータから時空間的な依存関係を学習し、その汎用的な能力によって自動運転システムにおける様々なタスクに応用することが期待されています。
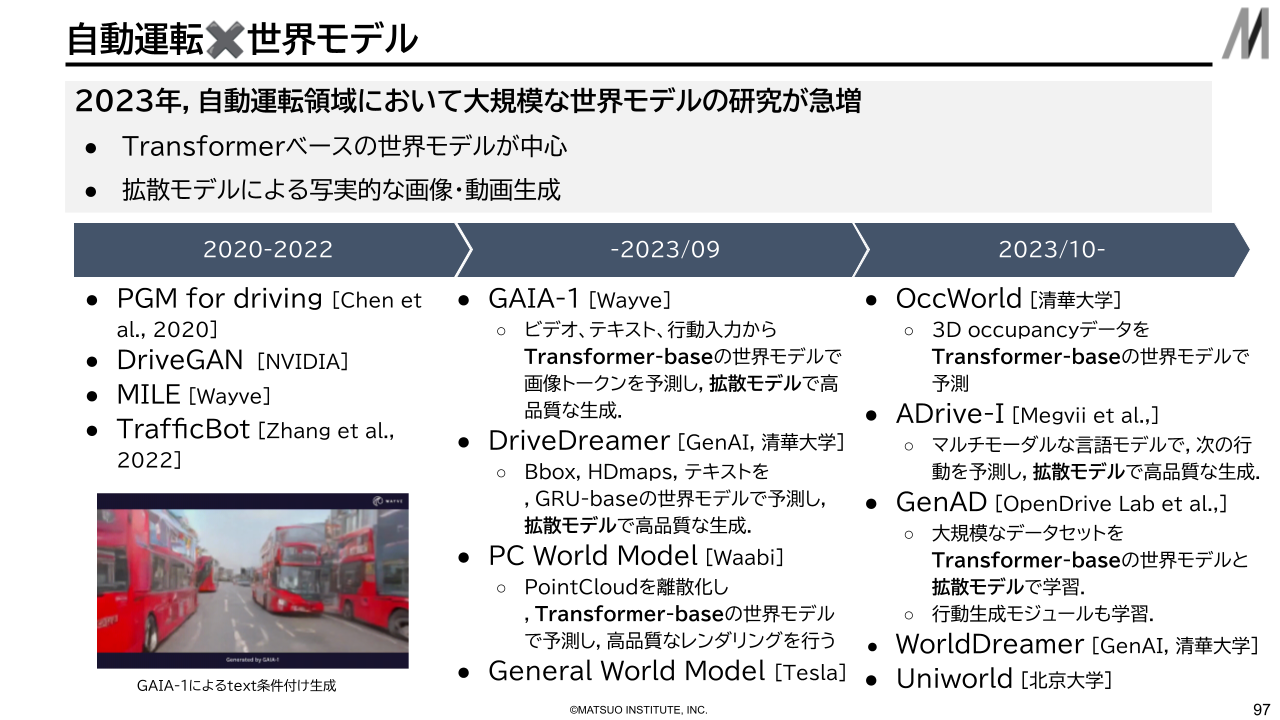
自動運転領域への世界モデル応用例
LLMで使用されるTransformerは、物体認識など自動運転車のセンサーデータの処理にも応用されています。Transformerは、長い依存関係の学習と、RGB画像とテキストデータなど多様なデータタイプの統合に優れています。また、LLMで見られているスケール則もTransformerベースの世界モデルで報告されており、より大規模にした場合の性能向上が期待されています。
本年度の取り組み
このような背景から、本共同研究では、まず初期的な検証としてCARLAのデータを用いて、Transformerベースの世界モデルを構築することを目標としました。全体のアーキテクチャはWayveのGAIA-1を参考にしています。具体的には、まずTransformerで画像の潜在表現を予測させるためにImage Tokenizerを用いて画像を離散ベクトルに埋め込む必要があります。今回はImage TokenizerとしてGAIA-1でも使用されていると考えられるVQVAEを用いました。Image Tokenizerで64*64の画像を1024種類、768次元の離散表現(画像トークン)に埋め込みます。今回はVQVAEの量子化ロスに加えて、セマンティックな表現を持った画像トークンを獲得するために、DINOの蒸留ロスを画像トークンに対して行っています。これにより教師なしでImage Tokenにセマンティックな情報が学習されることがわかります(下図上)。また、この蒸留ロスにより世界モデルの性能も向上することがわかっており、画像トークンにはセマンティックな表現が含まれることで後続のタスクに有用であることがわかります。この画像トークンと行動データと結合した2モダリティのデータをTransformerに入力します。(下図下)Transformerでは次のframeの画像トークンを予測することで、世界のダイナミクスを学習させます。
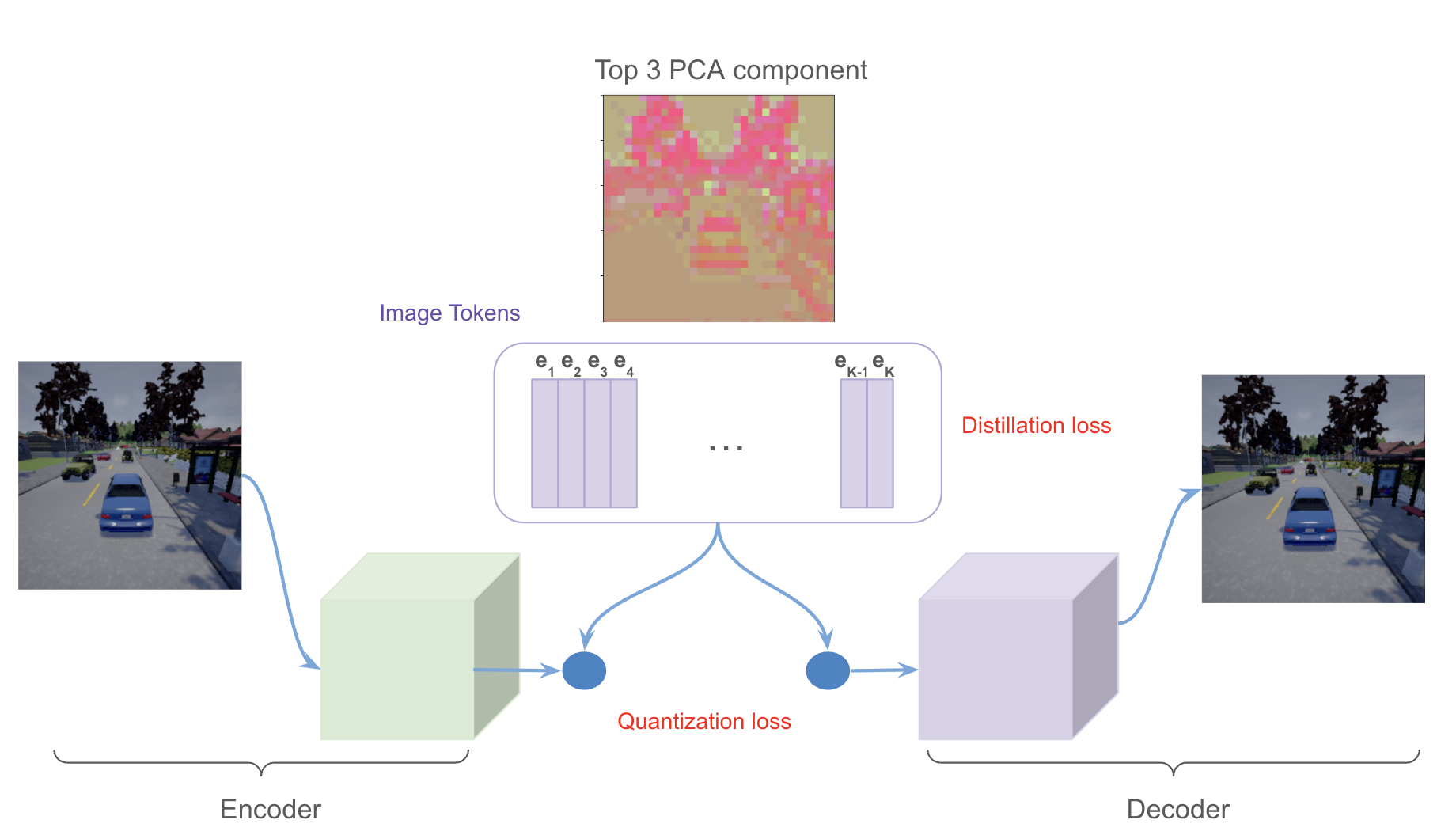
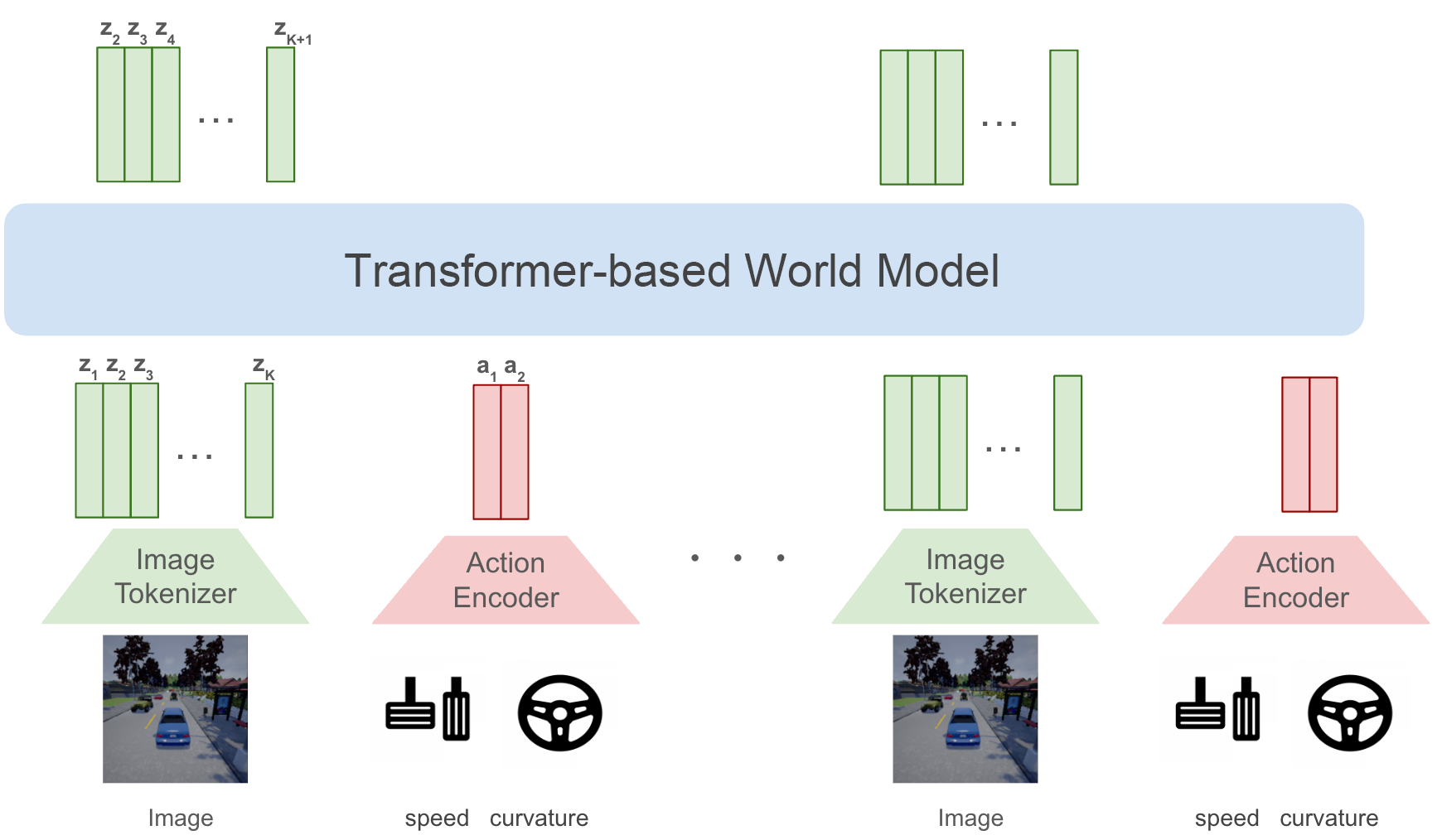
Transformerベースの世界モデルアーキテクチャ
以下の画像は実際に学習したTransformerが世界のダイナミクスを学習できているか確認するため、学習時にはありえない行動データを入力した世界を予測させています。具体的には、ハンドルを左右にふらつかせるような行動を入力しています。Transformerが予測した動画は、ハンドルの動きに応じて環境に対する相対的な自車両の位置が変わっていたり、道路が入力したハンドルの動きに応じて曲がって生成されており、「ハンドルを曲げると環境がどうなるか」が学習されていることがわかります。


世界モデルの予測 (左) 元の動画 (右)
今後の展望
本記事の内容は2023年時点の結果であり、まだ原理検証段階にあります。モデルサイズも小さく、データも現実世界の高解像度なデータを使用したものではありません。しかし、今回の取り組みは学習済みモデルを使わずに全てフルスクラッチで行っており、アーキテクチャ設計に制約がなく、より多様なデータ、モダリティに拡張(カスタマイズ)することが可能です。
2024年9月時点においても、高解像度な実世界データをもとにフルスクラッチで学習したDiffusionモデルをDecoderとして利用することで、Image Tokenから高品質に生成できる結果が得られています。今後も実世界データへの適用を進めながら、テキストモダリティの導入、さらにはLiDAR、Bounding Box、HDMapなどのモーダルも追加していき、より大規模なマルチモーダル世界モデルを構築していく予定です。


Diffusionモデルによる予測 (左) 元の動画 (右) (赤枠: 条件付けフレーム)
おわりに
自動運転技術における次なる大きなトレンドとして、LLMや生成AIを活用した「世界モデル」の応用が注目されています。これはテクノロジーの進化において逃すことのできない大きな流れです。私たちはこの革新的な波に積極的に乗り出し、自動運転における世界モデルの構築に挑戦しています。
この先端技術を共に推進し、研究を深めていくために、私たちは新たなチームメンバーを募集中です。自動運転の未来を創ることができるこの機会に、熱意と技術を持って貢献できる方の参加をお待ちしています。技術の最前線で活躍したいと考えている皆さん、ぜひ私たちの研究に参加し、共に新しい歴史を作り上げましょう。
過去の記事はこちら
ティアフォーでは、「自動運転の民主化」というビジョンに共感を持ち、自らそれを実現する意欲に満ち溢れた新しい仲間を募集しています。
今回のチームで募集中の職種
ティアフォーではAI関連の職種を多く採用をしています。詳細は、ティアフォーの「求人ページ」をご覧ください。
「どの職種で自分の経験を活かせるかが分からない」「希望する職種が見つからない」などの場合は、ぜひ「キャリア登録」をお願いします。
お問い合わせ先
- メディア取材やイベント登壇のご依頼:pr@tier4.jp
- ビジネスや協業のご相談:sales@tier4.jp
ソーシャルメディア
X (Japan/Global) | LinkedIn | Facebook | Instagram | YouTube
関連リンク