
ティアフォーと松尾研究所は、2020年から共同研究を開始し、2025年で6年目を迎えました。本共同研究では自動運転レベル5の実現を目指し、短期テーマと長期テーマという2つの時間軸で課題解決に取り組んでいます。
短期テーマでは、ティアフォーが開発を主導する自動運転用のオープンソースソフトウェア「Autoware」の機能改善に取り組んでいます。具体的には、松尾研究所が持つ深層学習に関する知見を活かし、自動運転の現場に近い立場から、「Autoware」が有するモジュールの認識精度や予測精度の改善などを進めています。
一方、長期テーマでは、松尾研究所が注力している「世界モデル」の自動運転領域への応用に取り組んでいます。世界モデルは、観測情報から実世界の変化を学習するモデルです。この技術を自動運転領域に応用することで、より高次な自動運転技術の実現に貢献できると考え、基礎研究的な立場から研究開発を進めています。
本記事を含め2回にわたり、2024年度のティアフォーと松尾研究所の共同プロジェクトの内容を紹介します。第1回となる今回は、長期テーマの取り組みについてご説明します。
長期テーマの取り組みを山口万瑛さん、峰岸剛基さんのメンバーで報告し、本記事ではその概要の一部をお伝えします。
長期テーマでは、松尾研究所が注力している「世界モデル」の自動運転分野への応用を目指しています。
世界モデルは、観測された情報に基づいて世界の構造を学習するモデルです。自己教師あり学習を通じて、空間的・時間的にコンパクトな「潜在表現」を獲得します。これにより、世界の刺激(環境や状況)を効率的に表現できるのが特徴です。
世界モデルの技術は世界的に注目されており、自動運転業界では、WayveがGAIA-2(GAIA-1の後継)を発表したり、NVIDIAがCosmosというオープンな世界モデルを公開しています。アカデミアでも、ICLRやICMLなどのトップ国際会議で世界モデルに関するワークショップが開催されています。
- ICLR2025: https://sites.google.com/view/worldmodel-iclr2025/
- ICML2025: https://physical-world-modeling.github.io/
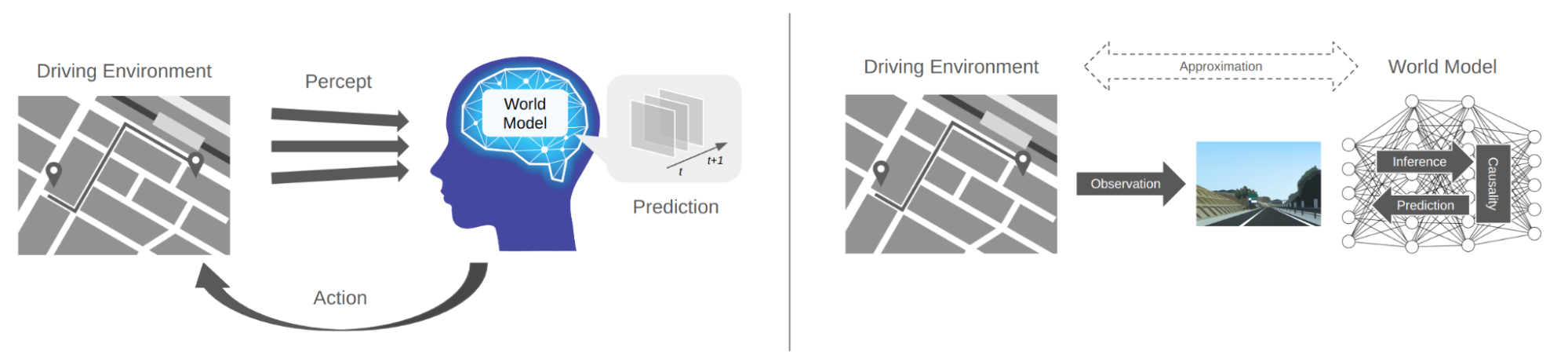
世界モデルの概念図
今回のプロジェクトでは、世界モデルの自動運転への応用について、以下の2つの取り組みに焦点を当てました。
1つ目は、世界モデルの要素技術として、Neural Radiance Fields(NeRF)ベースのデータ駆動型シミュレーターの開発です。NeRFや3D Gaussian Splatting(3DGS)の登場により3次元再構成が精巧になっていくにつれ、自動運転ドメインでの再構成手法やシミュレーターとしての実用可能性も盛んに研究されるようになりました。本研究では、2023度の共同研究をより発展させ、「交通参加者を含めた」、「大規模シーンにおける」再構成と評価を行うNeural Simulatorの実現に取り組みました。
2つ目は、データの再構成だけでなく、任意のシーンを生成するためのTransformerベースの世界モデルの構築です。具体的には、アクション、カメラ画像、テキスト、ポイントクラウド、HDマップなどの時系列情報を、自己教師あり学習(未来予測)を通じて世界の構造を学習する世界モデルを目指しています。2024年度は2023年度のシミュレーター空間での初期検証を実世界データに発展させ、高解像度データにおける高品質なシーン生成に取り組みました。
ニューラルシミュレーター
背景
近年、自動運転技術の安全性評価においては、仮想環境を用いたシミュレーションが不可欠な手法として定着しつつあります。しかし、従来の手法では、現実に即した走行環境を再現するために多くの人手や時間などのコストがかかります。
この課題を解決する方法として注目されているのが「データ駆動型のシミュレーション」です。深層学習技術を用いたNeRFは、3次元空間上の位置とカメラの視点からRGB画像や空間密度を推定できることから、写実的かつ高精度なシーン再構成技術として注目を集めました。また、最近では、3DGSが台頭し、より高速で高性能な画像再構成が可能となりました。しかし、自動運転ドメインにおいて、データ駆動型シミュレーションの実用性を評価する研究は、未だに不十分です。
2023年度の共同研究では、NeRFをベースとした、StreetSurf [Jianfei Guo+, arXiv:2306.04988] と呼ばれる手法を用い、背景のみをシミュレーションした後に実データと比較した評価を行いました。評価段階では、センサーレベルでの再構成誤差の評価に加え、3次元物体検出タスクを通じた再構成評価も行いました。
本研究では、さらに一歩進んで「交通参加者を含めた」、「大規模シーンにおける」再構成と評価を行うNeural Simulatorの実現に取り組みました。
NeRFや3DGSによる自動運転走行シーン再構成
NeRFは2020年に登場して以来、その高い表現力から、新視点の再構成技術として、注目を集めてきました。当初は静的かつ小規模なシーンに限定されていましたが、その後、再構成の広域化を目指したBlockNeRF [Matthew Tancik+, 2022]や、LiDARデータを活用可能としたUrban Radiance Fields [Konstantinos Rematas+, CVPR 2022]など、自動運転ドメインへの適用を意識した多様な手法が提案されてきました。
そして2023年以降、新たに台頭してきたのが3DGS [Bernhard+、SIGGRAPH 2023]です。これはNeRFとは異なり、明示的なガウス分布による3D表現を用いることで、高精細かつリアルタイム性能を兼ね備えた再構成を実現する手法です。
また、従来は背景のみをシミュレーションするモデルがほとんどでしたが、NeRFや3DGSを使って、車両や歩行者などの動物体を高精度に再構成する手法も登場しました。この流れに沿って、StreetSurfは、2024年4月に動物体を含めて学習できるコードを公開しました。
さらに近年は、再構成されたシーンを使って、自動運転アルゴリズムの評価に活用する試みも始まっています。その代表例としては、NeRFベースのシーンを用いてNew Car Assessment Program(NCAP)に準じた評価を行うNeuroNCAP [William+, ECCV 2024]などが挙げられます。
このように、データ駆動型シミュレーションは、自動運転技術の検証において重要な技術基盤となりつつあります。
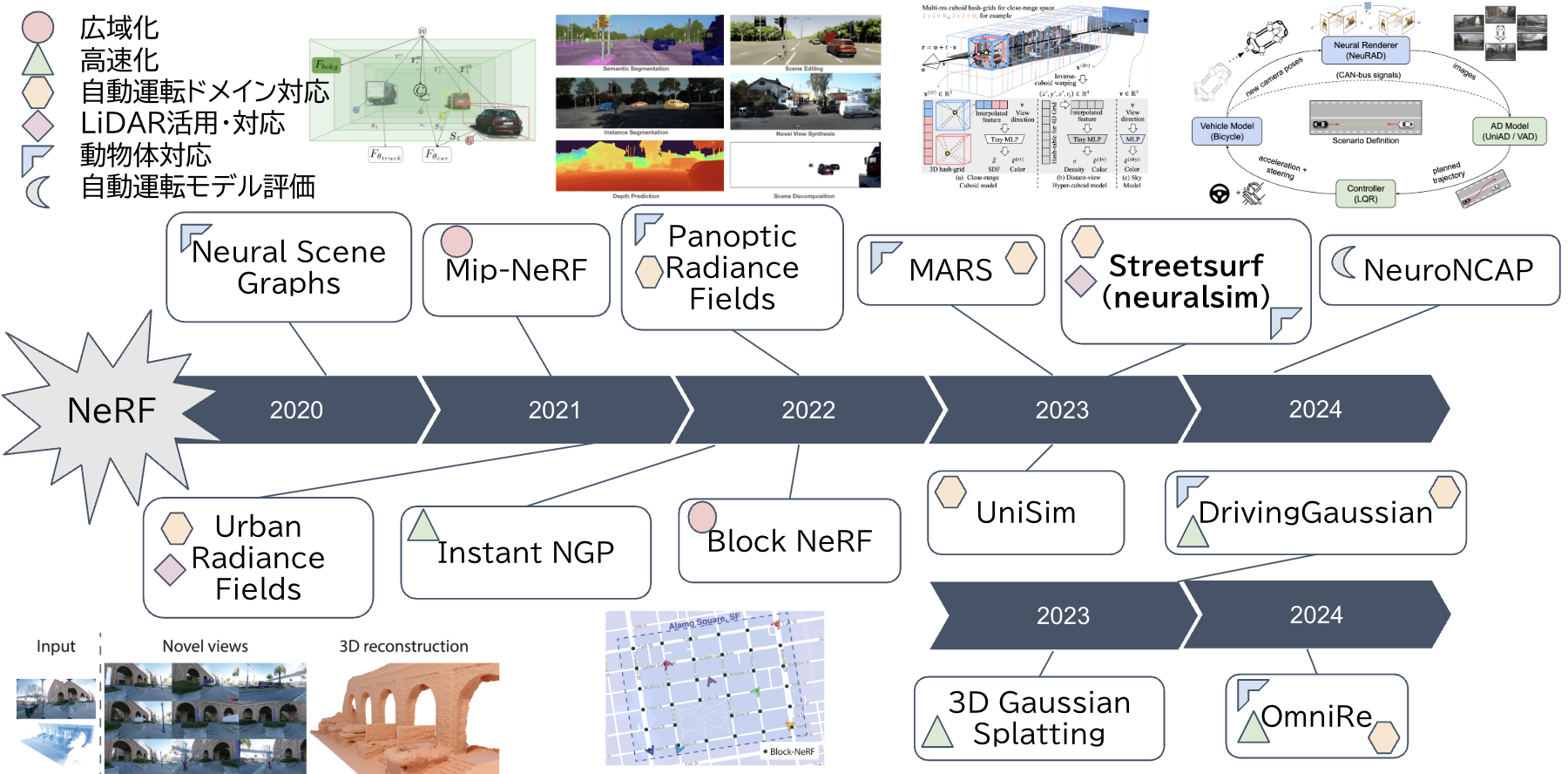
NeRFや3DGSによる自動運転走行シーン再構成における研究動向
2024年度の実施内容
このように自動運転技術の評価手法として、NeRFや3DGSで作成したシミュレーターを活用する動きが活発化しています。
本共同研究では、2023年度、LiDARデータを学習に取り入れた再構成手法(例:Urban Radiance Fields)の再現実装を行い、さらにStreetSurfをベースとしたNeural Simulatorによって生成されたシーンを用いて、自動運転アルゴリズムの性能を評価する取り組みを実施しました。ただし、当時の再構成対象は背景に限定されており、動物体の取り扱いには至っていませんでした。
そこで2024度は、再構成対象を動物体(車両・歩行者など)にも拡張することで、実環境を包括的に再構成したNeural Simulatorの評価を実現しました。背景と動物体の両方を統一的に再構成することで、現実に近いセンサー出力が得られ、より信頼性の高い自動運転アルゴリズムの評価が可能となっています。また、評価段階ではセンサーレベルでの再構成誤差の評価に加え、物体検出タスクを通じた再構成評価も行いました。
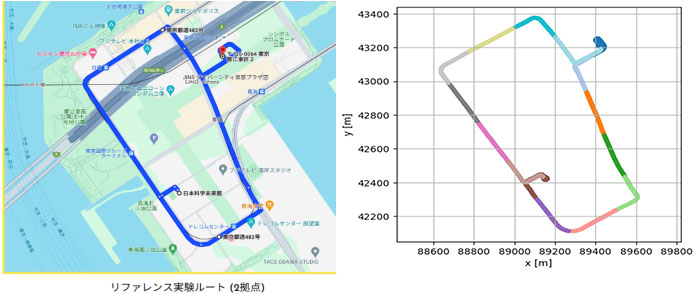
さらに今回は、単一シーンだけでなく、お台場の周回データ全体を用いた大規模な再構成にも取り組みました。長時間・長距離の連続的な走行環境においてもシミュレーション精度が保たれることを確認しました。
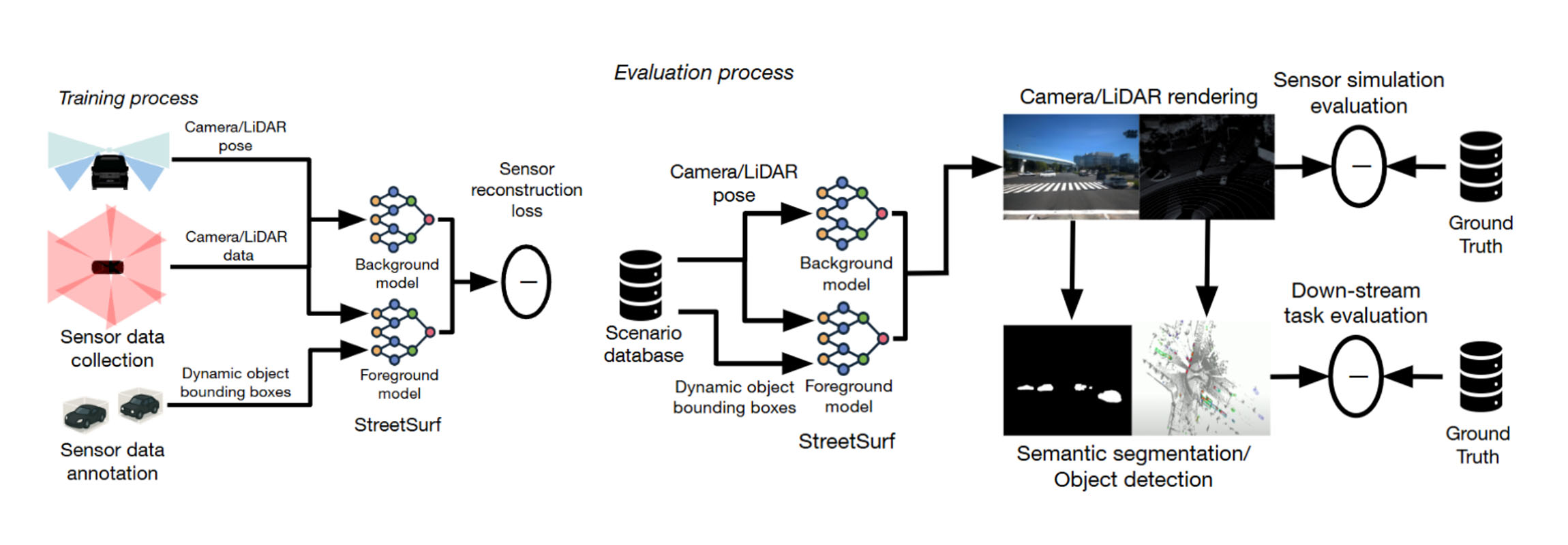
動物体を含めたNeural Simulatorの構成と学習評価のプロセス
StreetSurfによる動物体を含む再構成
センサーレベルにおける再構成評価
以下に、センサーレベルでの再構成精度評価の結果を示します。画像の再構成に対してはPeak Signal-to-Noise Ratio(PSNR)およびStructural Similarity Index Measure(SSIM)を、点群の再構成にはChamfer Distanceを指標として用いました。Chamfer Distanceは、予測された点群とGround Truth点群との距離を表し、形状の再現精度を定量的に評価するものです。
本評価では、学習に用いた軌道(学習軌道)と、一部のタイムスタンプをスキップして再構成を行った軌道(スキップ軌道)の2種類を比較対象としました。その結果、スキップされた地点、すなわち学習軌道から多少離れた位置においても、画像の再構成精度に大きな劣化は見られず、相対的に高い写実性が維持されていることが確認されました。

カメラ画像の再構成における比較結果
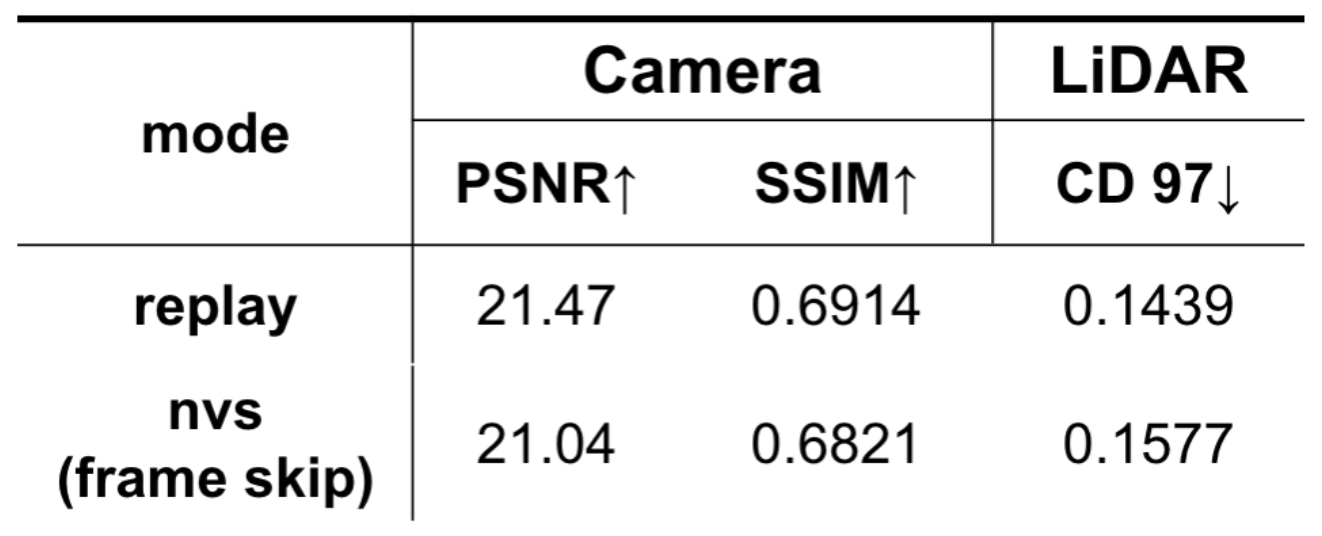
センサーレベルの再構成における精度評価結果
物体検出タスクにおける評価
物体検出タスクによる評価では、セマンティックセグメンテーション(Semantic Segmentation)を通した2次元物体検出と、Centerpointを通した3次元物体検出を行いました。
まず、Semantic Segmentationによる推論結果を示します。下図は、左から順にGround Truth画像、予測画像、学習時にスキップされた視点からの予測画像、そして視点を1 m移動させた際の予測画像を示しています。注目すべき点は、1 m程度の視点移動に対しても、再構成結果のSemantic SegmentationにおけるIntersection over Union(IoU)が学習軌道と同程度を維持していることです。
この結果から、本手法はカメラ視点の変動に対して高いロバスト性を持ち、視点外挿においても意味的な構造を保った画像再構成が可能であることが確認されました。

Semantic Segmentationタスク出力の比較結果
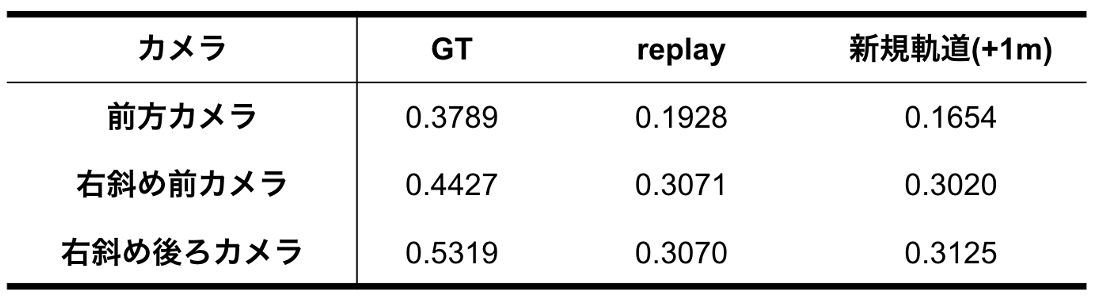
Semantic Segmentationタスクにおける評価結果
続いて、3D物体検出モデルであるCenterPointを用いて車両を検出した際の結果です。背景および動物体(車両)をそれぞれGround Truth(GT)および予測(Pred)の点群として使用し、検出精度を比較しました。
下図はその可視化結果を示しています。点群に関しては、青色がGTに対して誤差の小さい点群、赤色がGTに対して誤差の大きい点群を表しています。また、緑のバウンディングボックスがGT、青のバウンディングボックスはGT点群に対するCenterPoint推論結果、赤のバウンディングボックスがPred点群に対するCenterPoint推論結果に対応しています。

LiDARの物体検出結果
結果として、自車に近い領域では比較的高精度な物体検出が行われており、予測と実際の車両位置が一致していることが確認されました。一方で、自車から離れた領域では、道路外に誤って車両を検出するなど、誤検出も見られました。これは、再構成点群の密度や精度が距離に応じて変化することが影響していると考えられます。
大規模シーンにおける再構成
大規模な走行環境を高精度に再構成するため、本研究ではBlock-NeRF [Matthew Tancik+, 2022]を参考に、モデルの空間分割とレンダリング結果のマージを組み合わせた手法を採用しました。
まず、お台場1周分の走行データを距離に応じて15分割し、各モデルを学習させます。推論時には、レンダリング対象地点に対して隣接する複数の再構成モデルを選択し、各モデルによるレンダリング結果を2次元逆距離加重平均(2D Inverse Distance Weighting:2D-IDW)によって統合します。
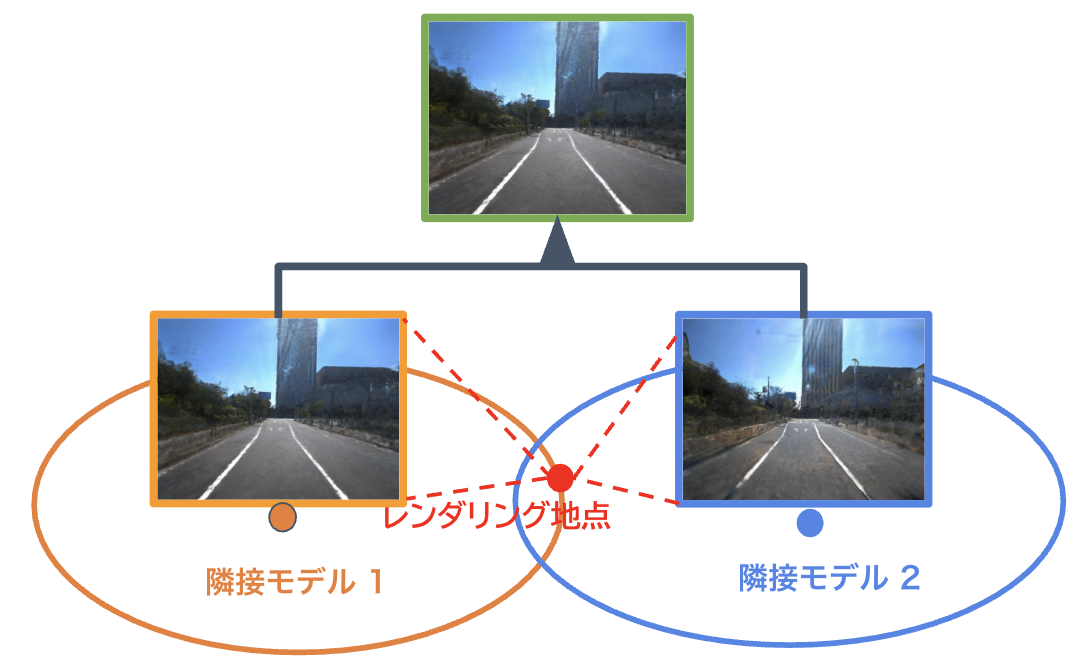
Block-NeRF [Matthew Tancik+, 2022]を参考にした大規模化手法
実際、お台場周回のreplay軌道全体における評価では、2D-IDWによるマージを行った場合(マージあり)は、単一モデルによる再構成(マージなし)と比較してPSNRおよびSSIMが改善しました。これは、モデル接続部分の再構成精度が大幅に向上したことを示しています。

大規模化手法(2D-IDW)の評価結果
今後の展望
今後は、車両などの動物体のより高精細な再構成を目指すとともに、データ駆動型シミュレーターにおけるさらなる柔軟性の実現に取り組みます。
具体的には、動物体データベース(DB)を活用して、既存シーンに新たな動物体を動的に挿入・置換できる機能が考えられます。例えば、1つの動物体を個別に学習し、既存のシーン中の動物体と置き換えて再レンダリングした結果を以下に示します。


左:GT(動物体DB)、右: Pred(動物体DB)

左:GT、中央: Pred、右: Pred(Depth)
このような手法により、既存のデータを元にした固定的な再構成に止まらず、多様な交通状況を反映させた柔軟なシミュレーションが可能となることが期待されます。
Transformerベース世界モデル
世界モデルの研究動向とコア技術
自動運転向けの世界モデル研究はここ数年で急速に進み、欧州や中国の企業や大学を中心に数十〜数百億パラメーター級のモデルが次々と報告されています。最新の世界モデルのコアアーキテクチャは大きく二系統に収束しつつあり、さらに両者を融合したハイブリッド方式のモデルも登場しています。
まず、Transformer系はセンサー列と行動列を時系列トークンとして扱い、自己回帰的に未来のトークンを予測します。大規模言語モデル(Large Language Model:LLM)に類似したアーキテクチャであり、LLM研究で得られた知見をそのまま移植できる点が大きな強みです。
一方、Diffusion系は圧縮された潜在表現をノイズから復元するプロセスを学習するモデルです。OpenAIのSoraなどで実証されているアーキテクチャであるため、シミュレーションシーンでもフォトリアリスティックな品質が期待できます。
そしてこの二つを組み合わせたハイブリッド型は、Transformerが将来状態をコンパクトな潜在表現で出力し、Diffusionがそれを高品質な映像へデコードする分業構成により、「精度の高い未来予測」と「フォトリアリスティックな生成」を実現しています。実運用を視野に入れた最新プロジェクトの多く(例:GAIA-1、Cosmos)が、この構成を採用しています。
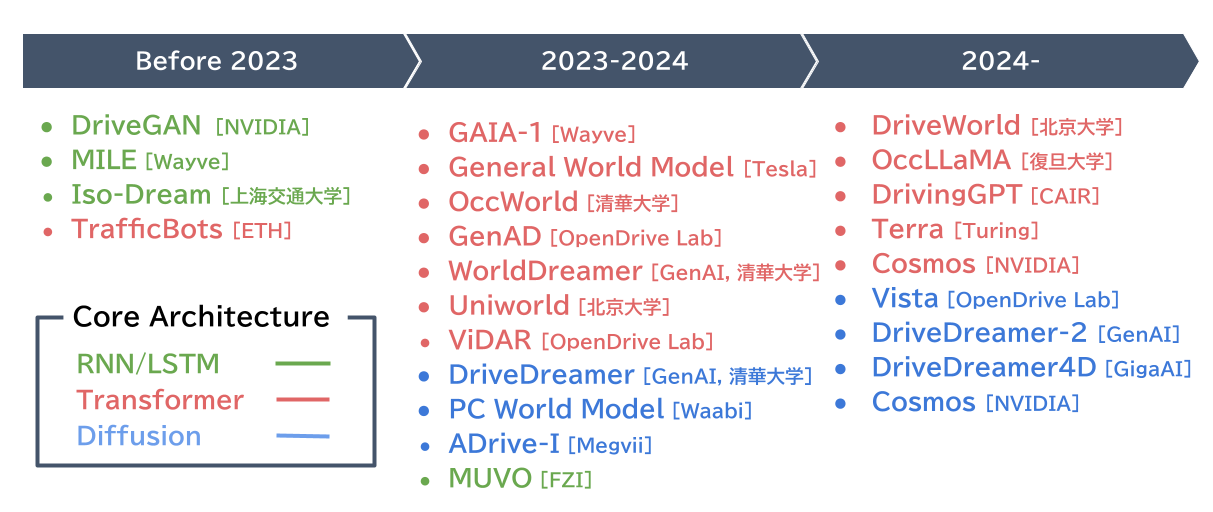
自動運転向けの世界モデルにおける研究動向
汎用基盤モデルとしての世界モデル
上述のとおり、最新の世界モデルは巨大なTransformerで未来状態を予測し、その潜在をDiffusionモデルで高精細な映像へデコードする二段構成が主流となっています。この世界モデル自体の学習は基本的にはアノテーションフリーのため、大量データでの学習が可能で環境を理解した世界モデルが構築できます。この環境を理解した世界モデルは、自動運転の実際のタスクであるSimulationやPrediction、Planningなどに幅広く応用が可能で、汎用的な基盤モデルになることが期待できます。
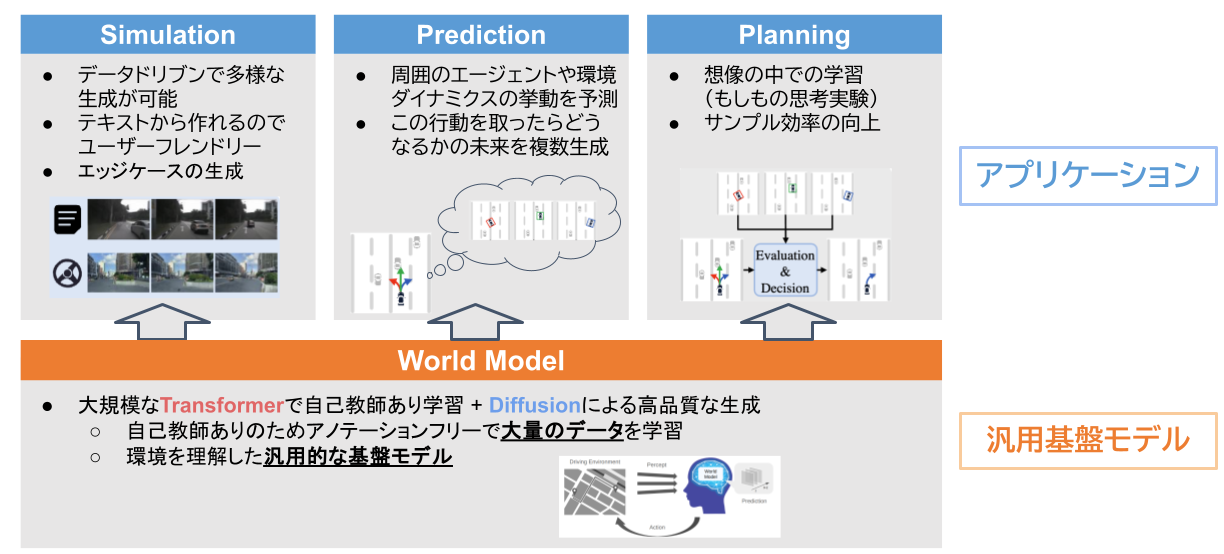
汎用基盤モデルとしての世界モデルの活用
2024年度の取り組み
このような背景から、2024年度は実環境の自動運転データセットnuScenesを用い、Transformerベースの世界モデルを構築することを目指しました。アーキテクチャは大きく3つの段階から成ります。
- 画像の離散トークン化(VQVAE)
まず、VQ-VAEによって入力画像を離散ベクトル空間へ埋め込みます。VQ-VAEの学習では、コードブックの利用が偏りやすいという課題が生じるため、勾配計算を工夫するRotational Trickを導入し、各コードの使用率を高めました。さらにGAIA-1の手法に倣い、画像トークンにセマンティックな表現を付与する目的でDINOの蒸留ロスを併用しています。
- トークンの未来予測(Transformer)
- 高解像度画像への復元(拡散モデル)
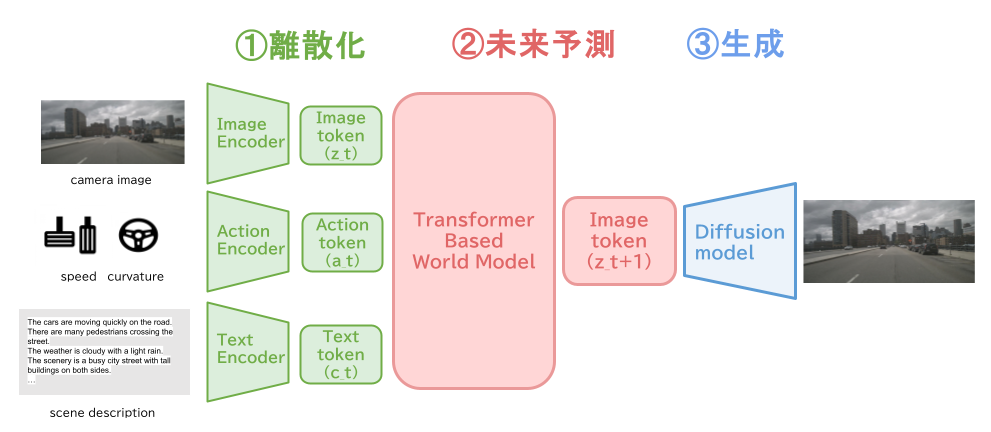
Transformerベース世界モデルのアーキテクチャ
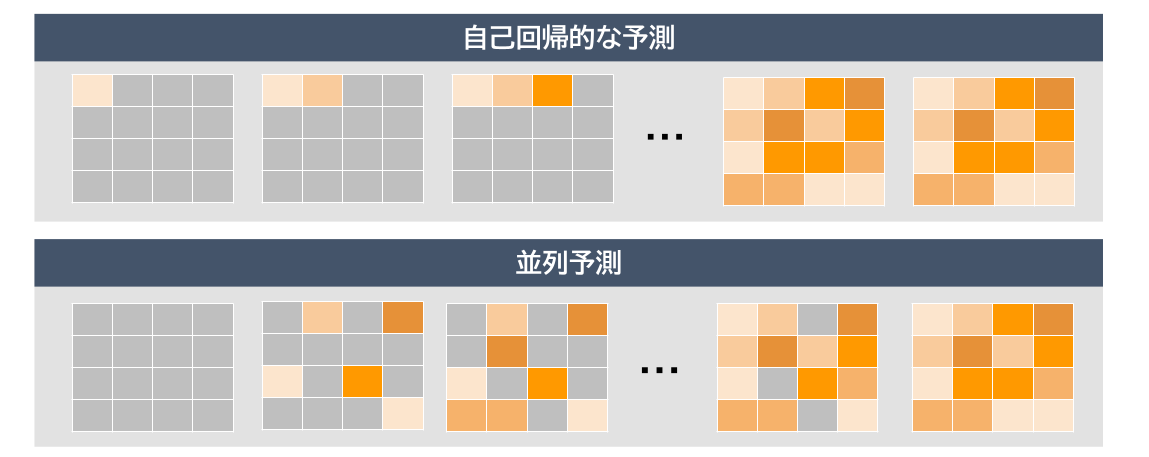
トークンの未来予測における方策
下の図(左)が初めの3フレームを条件づけて残りの9フレームを世界モデルで予測した結果です。ここで初めの3フレームは訓練データを使用しています。背景や道路など全12フレームを通じて高品質でかつ一貫した生成ができていることがわかります。


世界モデルでの予測結果 (左:予測結果、右:元動画)
下の図は初めの3フレームをテストデータ(世界モデルが未知のデータ)を使って、残りの9フレームを生成させた結果です。見たことのないデータが入力された場合もその続きをもっともらしく生成できていることがわかります。ここから世界モデルが自動運転ドメインにおける環境を理解していることが推測されます。


世界モデルでの予測結果(左:予測結果、右:元動画)
今後の展望
本共同研究では、実際の自動運転走行データを用い、Transformerベースの世界モデルを構築しました。2025年以降、GAIA-2やCosmosに代表されるように、拡散モデルやFlow-matchingをコアアーキテクチャに組み込む研究が主流となりつつあります。また、Bounding BoxやHD mapなど、条件付けに用いるモダリティも着実に増えています。今後は、こうした潮流を踏まえつつ、モダリティの拡張とモデルの大規模化をさらに推進していく予定です。
おわりに
本記事では、2024年度のティアフォーと松尾研究所の取り組みの成果の一部を紹介しました。次回は短期テーマの取り組み結果について紹介します。
過去の記事はこちら
ティアフォーでは、「自動運転の民主化」というビジョンに共感を持ち、自らそれを実現する意欲に満ち溢れた新しい仲間を募集しています。
今回のチームで募集中の職種
ティアフォーではAI関連の職種を多く採用をしています。詳細は、ティアフォーの「求人ページ」をご覧ください。
「どの職種で自分の経験を活かせるかが分からない」「希望する職種が見つからない」などの場合は、ぜひ「キャリア登録」をお願いします。
お問い合わせ先
- メディア取材やイベント登壇のご依頼:pr@tier4.jp
- ビジネスや協業のご相談:sales@tier4.jp
ソーシャルメディア
X (Japan/Global) | LinkedIn | Facebook | Instagram | YouTube
関連リンク